giantsteps_mtg_key
This is the tempo_eval report for the ‘giantsteps_mtg_key’ corpus.
Reports for other corpora may be found here.
Table of Contents
- References for ‘giantsteps_mtg_key’
- Estimates for ‘giantsteps_mtg_key’
References for ‘giantsteps_mtg_key’
References
1.0
| Attribute | Value |
|---|---|
| Corpus | GiantSteps MTG Key |
| Version | 1.0 |
| Curator | Hendrik Schreiber |
| Annotation Tools | manual annotation |
| Annotator, bibtex | Schreiber2018a |
| Annotator, ref_url | http://www.tagtraum.com/tempo_estimation.html |
Basic Statistics
| Reference | Size | Min | Max | Avg | Stdev | Sweet Oct. Start | Sweet Oct. Coverage |
|---|---|---|---|---|---|---|---|
| 1.0 | 1157 | 52.00 | 198.00 | 124.92 | 23.20 | 90.00 | 0.89 |
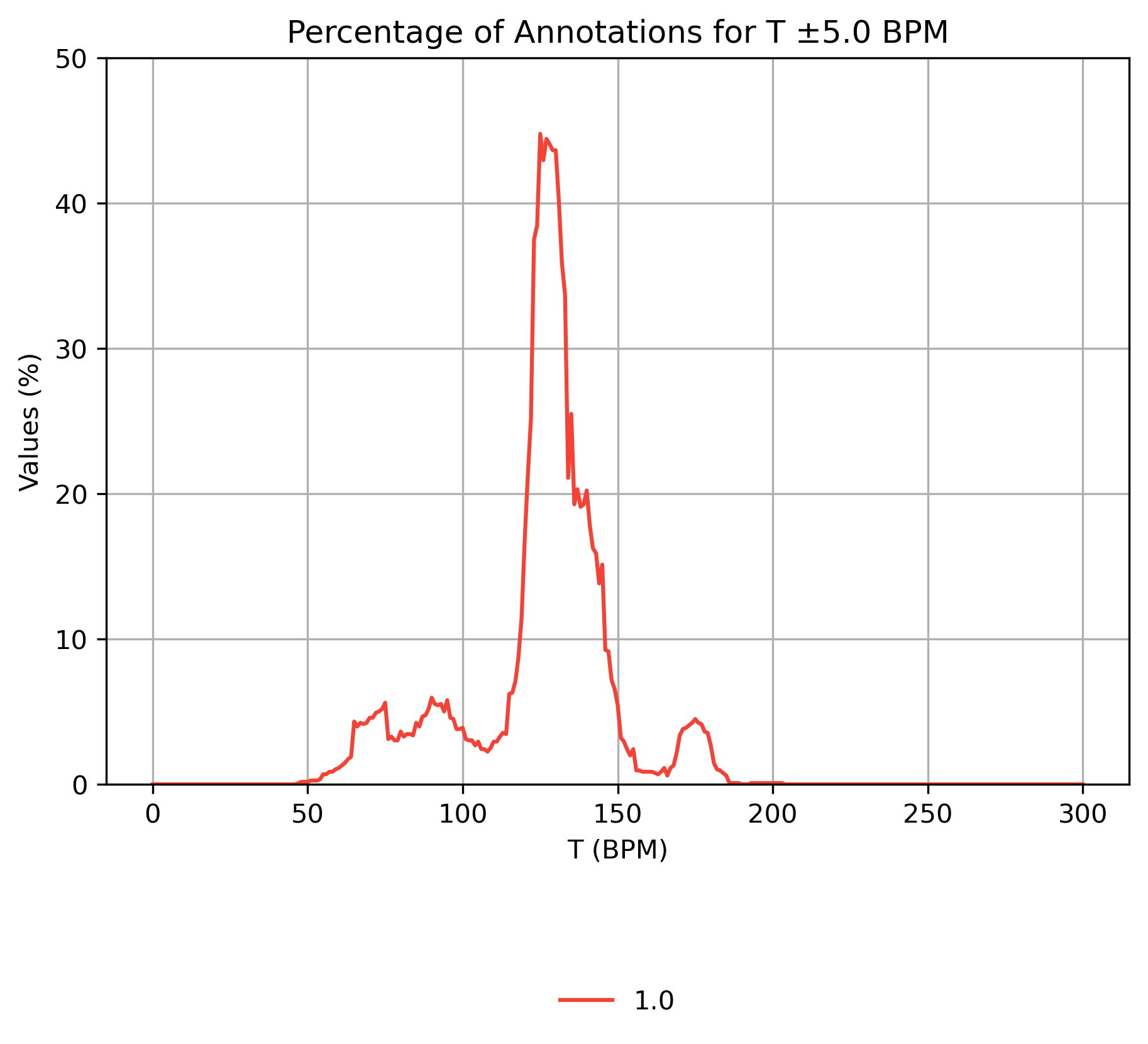
Smoothed Tempo Distribution
Figure 1: Percentage of values in tempo interval.
CSV JSON LATEX PICKLE SVG PDF PNG
{kind=link}
{kind=link}
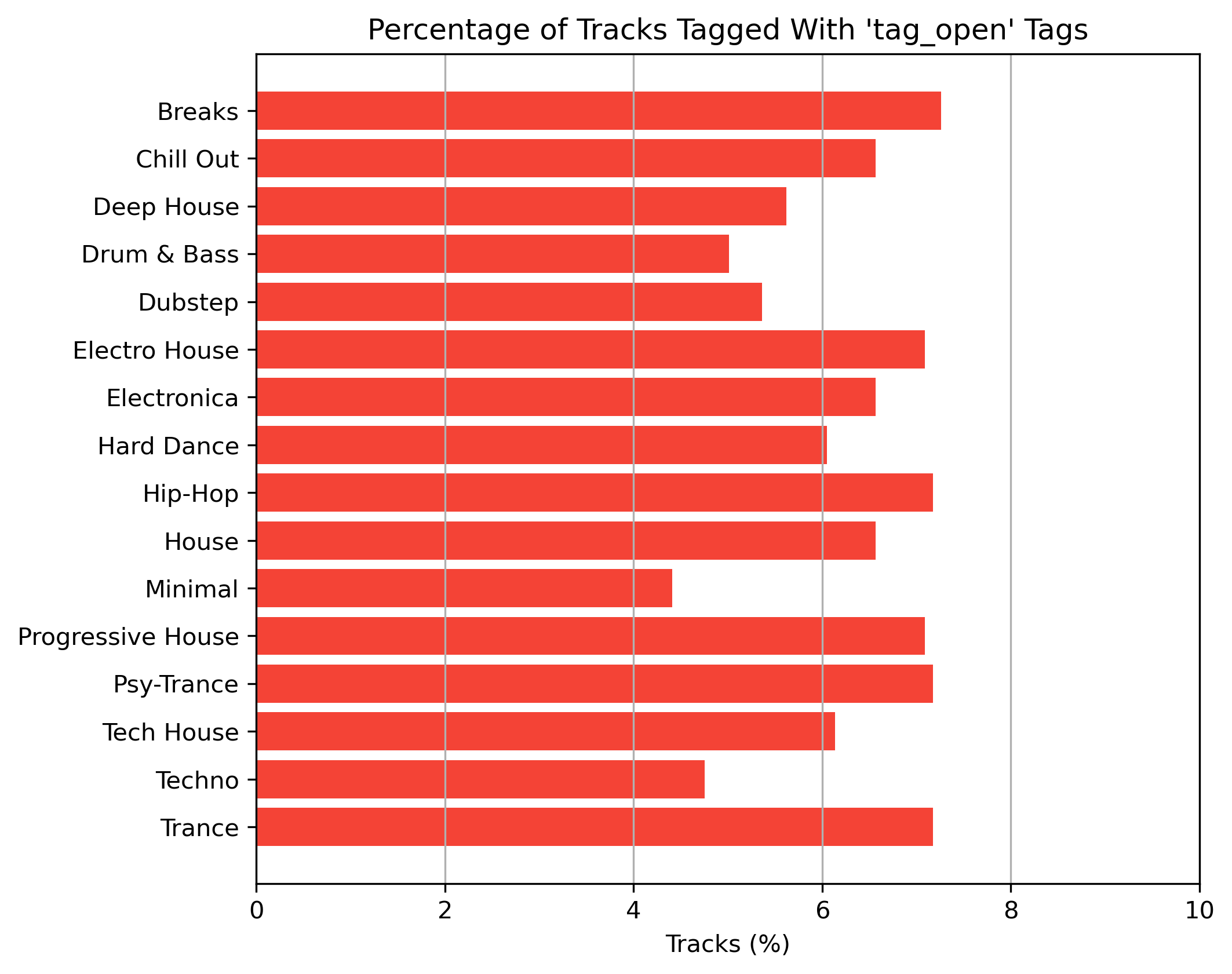
Tag Distribution for ‘tag_open’
Figure 2: Percentage of tracks tagged with tags from namespace ‘tag_open’. Annotations are from reference 1.0.
CSV JSON LATEX PICKLE SVG PDF PNG
{kind=link}
{kind=link}
Estimates for ‘giantsteps_mtg_key’
Estimators
boeck2015/tempodetector2016_default
| Attribute | Value |
|---|---|
| Corpus | giantsteps_mtg_key |
| Version | 0.17.dev0 |
| Annotation Tools | TempoDetector.2016, madmom, https://github.com/CPJKU/madmom |
| Annotator, bibtex | Boeck2015 |
davies2009/mirex_qm_tempotracker
| Attribute | Value | |
|---|---|---|
| Corpus | giantsteps_mtg_key | |
| Version | 1.0 | |
| Annotation Tools | QM Tempotracker, Sonic Annotator plugin. https://code.soundsoftware.ac.uk/projects/mirex2013/repository/show/audio_tempo_estimation/qm-tempotracker Note that the current macOS build of ‘qm-vamp-plugins’ was used. | |
| Annotator, bibtex | Davies2009 | Davies2007 |
percival2014/stem
| Attribute | Value |
|---|---|
| Corpus | giantsteps_mtg_key |
| Version | 1.0 |
| Annotation Tools | percival 2014, ‘tempo’ implementation from Marsyas, http://marsyas.info, git checkout tempo-stem |
| Annotator, bibtex | Percival2014 |
schreiber2014/default
| Attribute | Value |
|---|---|
| Corpus | giantsteps_mtg_key |
| Version | 0.0.1 |
| Annotation Tools | schreiber 2014, http://www.tagtraum.com/tempo_estimation.html |
| Annotator, bibtex | Schreiber2014 |
schreiber2017/ismir2017
| Attribute | Value |
|---|---|
| Corpus | giantsteps_mtg_key |
| Version | 0.0.4 |
| Annotation Tools | schreiber 2017, model=ismir2017, http://www.tagtraum.com/tempo_estimation.html |
| Annotator, bibtex | Schreiber2017 |
schreiber2017/mirex2017
| Attribute | Value |
|---|---|
| Corpus | giantsteps_mtg_key |
| Version | 0.0.4 |
| Annotation Tools | schreiber 2017, model=mirex2017, http://www.tagtraum.com/tempo_estimation.html |
| Annotator, bibtex | Schreiber2017 |
schreiber2018/cnn
| Attribute | Value |
|---|---|
| Corpus | giantsteps_mtg_key |
| Version | 0.0.2 |
| Data Source | Hendrik Schreiber, Meinard Müller. A Single-Step Approach to Musical Tempo Estimation Using a Convolutional Neural Network. In Proceedings of the 19th International Society for Music Information Retrieval Conference (ISMIR), Paris, France, Sept. 2018. |
| Annotation Tools | schreiber tempo-cnn (model=cnn), https://github.com/hendriks73/tempo-cnn |
schreiber2018/fcn
| Attribute | Value |
|---|---|
| Corpus | giantsteps_mtg_key |
| Version | 0.0.2 |
| Data Source | Hendrik Schreiber, Meinard Müller. A Single-Step Approach to Musical Tempo Estimation Using a Convolutional Neural Network. In Proceedings of the 19th International Society for Music Information Retrieval Conference (ISMIR), Paris, France, Sept. 2018. |
| Annotation Tools | schreiber tempo-cnn (model=fcn), https://github.com/hendriks73/tempo-cnn |
schreiber2018/ismir2018
| Attribute | Value |
|---|---|
| Corpus | giantsteps_mtg_key |
| Version | 0.0.2 |
| Data Source | Hendrik Schreiber, Meinard Müller. A Single-Step Approach to Musical Tempo Estimation Using a Convolutional Neural Network. In Proceedings of the 19th International Society for Music Information Retrieval Conference (ISMIR), Paris, France, Sept. 2018. |
| Annotation Tools | schreiber tempo-cnn (model=ismir2018), https://github.com/hendriks73/tempo-cnn |
Basic Statistics
| Estimator | Size | Min | Max | Avg | Stdev | Sweet Oct. Start | Sweet Oct. Coverage |
|---|---|---|---|---|---|---|---|
| boeck2015/tempodetector2016_default | 1485 | 41.67 | 230.77 | 111.39 | 31.51 | 72.00 | 0.74 |
| davies2009/mirex_qm_tempotracker | 1485 | 63.02 | 198.77 | 128.09 | 19.03 | 84.00 | 0.96 |
| percival2014/stem | 1485 | 56.95 | 160.25 | 114.19 | 23.92 | 72.00 | 0.89 |
| schreiber2014/default | 1485 | 59.00 | 174.98 | 119.78 | 21.69 | 75.00 | 0.93 |
| schreiber2017/ismir2017 | 1485 | 63.50 | 176.01 | 115.24 | 27.53 | 80.00 | 0.90 |
| schreiber2017/mirex2017 | 1485 | 48.18 | 187.99 | 125.25 | 20.21 | 76.00 | 0.93 |
| schreiber2018/cnn | 1485 | 60.00 | 195.00 | 126.52 | 21.04 | 88.00 | 0.92 |
| schreiber2018/fcn | 1485 | 52.00 | 237.00 | 127.74 | 21.34 | 90.00 | 0.93 |
| schreiber2018/ismir2018 | 1485 | 60.00 | 186.00 | 125.25 | 20.30 | 77.00 | 0.93 |
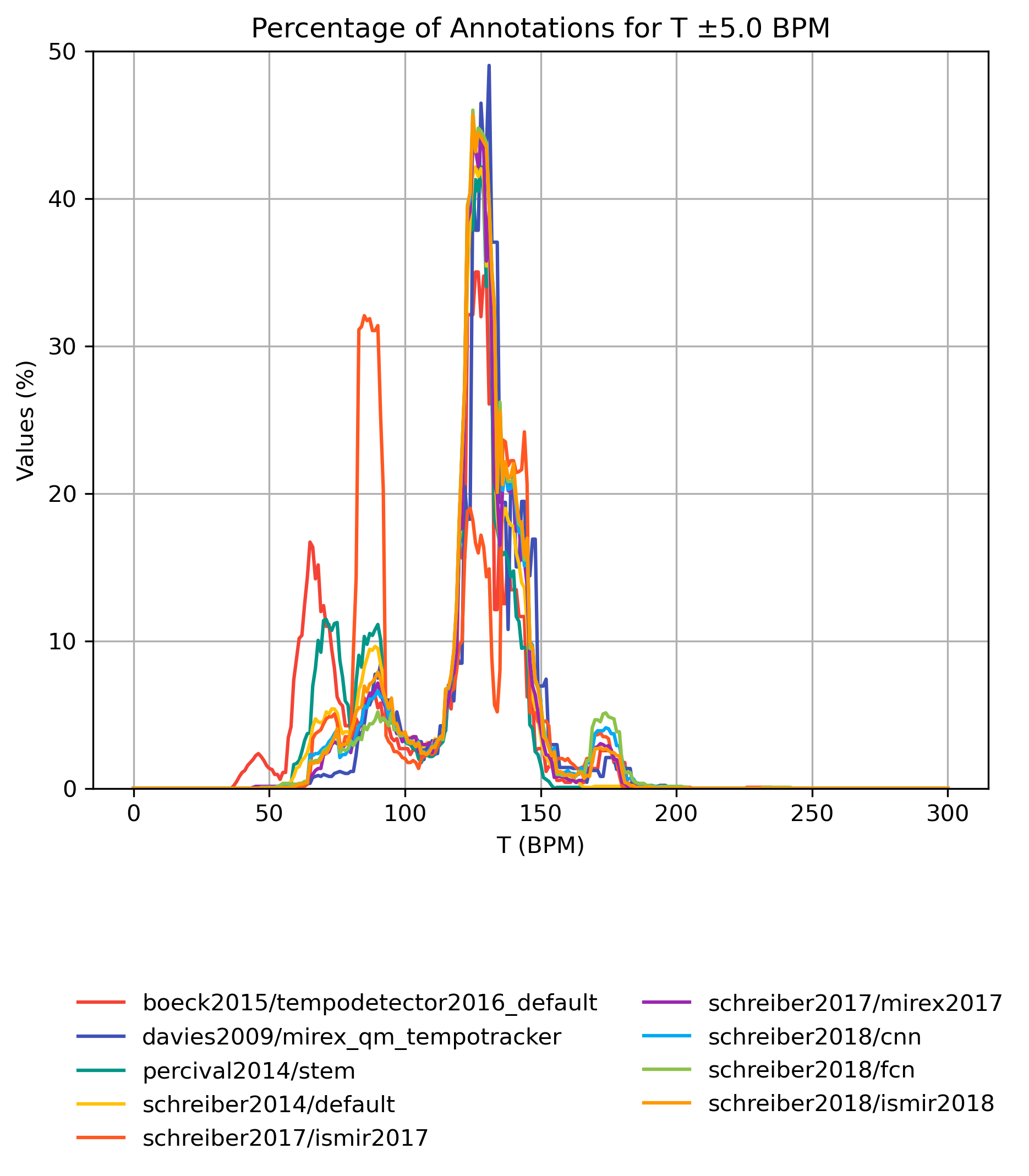
Smoothed Tempo Distribution
Figure 3: Percentage of values in tempo interval.
CSV JSON LATEX PICKLE SVG PDF PNG
{kind=link}
{kind=link}
Accuracy
Accuracy1 is defined as the percentage of correct estimates, allowing a 4% tolerance for individual BPM values.
Accuracy2 additionally permits estimates to be wrong by a factor of 2, 3, 1/2 or 1/3 (so-called octave errors).
See [Gouyon2006].
Note: When comparing accuracy values for different algorithms, keep in mind that an algorithm may have been trained on the test set or that the test set may have even been created using one of the tested algorithms.
Accuracy Results for 1.0
| Estimator | Accuracy1 | Accuracy2 |
|---|---|---|
| schreiber2018/cnn | 0.9404 | 0.9914 |
| schreiber2018/fcn | 0.9386 | 0.9914 |
| schreiber2018/ismir2018 | 0.9188 | 0.9914 |
| schreiber2017/mirex2017 | 0.8989 | 0.9810 |
| davies2009/mirex_qm_tempotracker | 0.8487 | 0.9507 |
| schreiber2014/default | 0.8444 | 0.9663 |
| percival2014/stem | 0.7934 | 0.9914 |
| boeck2015/tempodetector2016_default | 0.7580 | 0.9853 |
| schreiber2017/ismir2017 | 0.1478 | 0.1945 |
Table 3: Mean accuracy of estimates compared to version 1.0 with 4% tolerance ordered by Accuracy1.
Raw data Accuracy1: CSV JSON LATEX PICKLE
Raw data Accuracy2: CSV JSON LATEX PICKLE
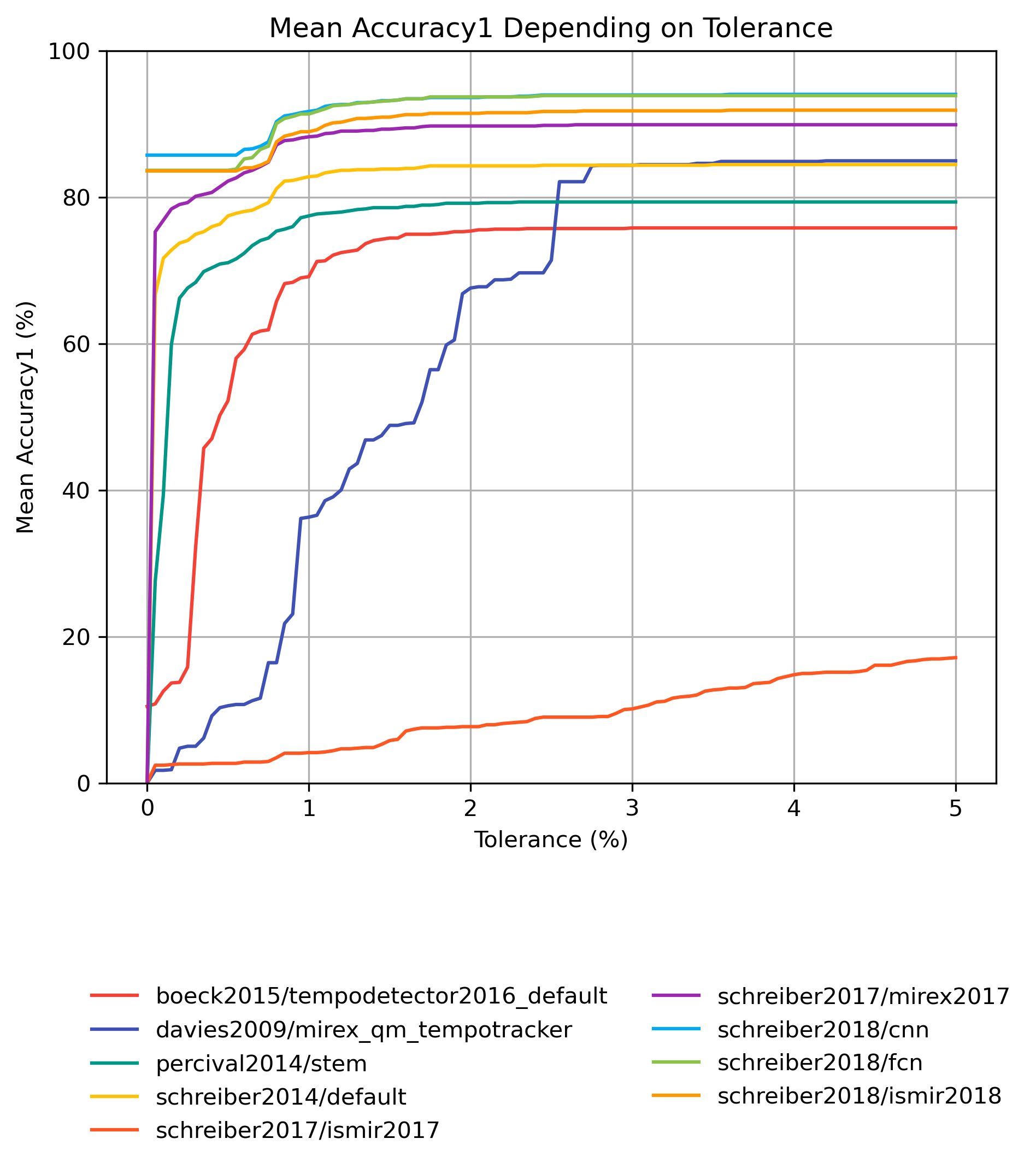
Accuracy1 for 1.0
Figure 4: Mean Accuracy1 for estimates compared to version 1.0 depending on tolerance.
CSV JSON LATEX PICKLE SVG PDF PNG
{kind=link}
{kind=link}
Accuracy2 for 1.0
Figure 5: Mean Accuracy2 for estimates compared to version 1.0 depending on tolerance.
CSV JSON LATEX PICKLE SVG PDF PNG
{kind=link}
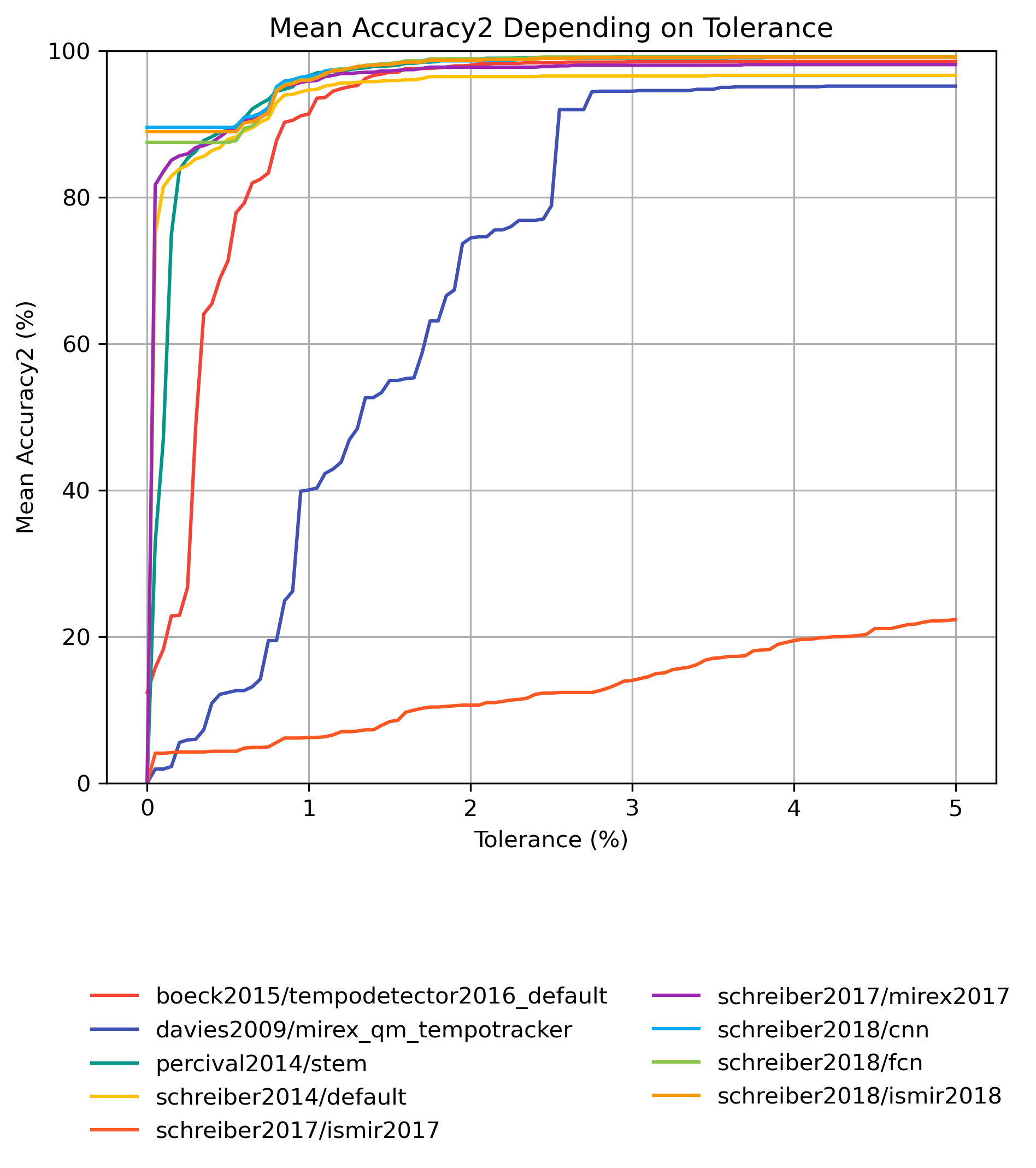{kind=link}
Differing Items
For which items did a given estimator not estimate a correct value with respect to a given ground truth? Are there items which are either very difficult, not suitable for the task, or incorrectly annotated and therefore never estimated correctly, regardless which estimator is used?
Differing Items Accuracy1
Items with different tempo annotations (Accuracy1, 4% tolerance) in different versions:
1.0 compared with boeck2015/tempodetector2016_default (280 differences): ‘1034722.LOFI’ ‘1038248.LOFI’ ‘110504.LOFI’ ‘1163534.LOFI’ ‘1164433.LOFI’ ‘1177887.LOFI’ ‘1190182.LOFI’ ‘1194397.LOFI’ ‘1194512.LOFI’ ‘119467.LOFI’ ‘1205438.LOFI’ … CSV
1.0 compared with davies2009/mirex_qm_tempotracker (175 differences): ‘1034722.LOFI’ ‘1059355.LOFI’ ‘1147737.LOFI’ ‘1163534.LOFI’ ‘1164433.LOFI’ ‘1185017.LOFI’ ‘1187324.LOFI’ ‘1205438.LOFI’ ‘1277819.LOFI’ ‘1288533.LOFI’ ‘1290726.LOFI’ … CSV
1.0 compared with percival2014/stem (239 differences): ‘1034722.LOFI’ ‘1038248.LOFI’ ‘103857.LOFI’ ‘11194.LOFI’ ‘1147737.LOFI’ ‘1156133.LOFI’ ‘1164433.LOFI’ ‘1177887.LOFI’ ‘1185017.LOFI’ ‘1187324.LOFI’ ‘1196189.LOFI’ … CSV
1.0 compared with schreiber2014/default (180 differences): ‘1034722.LOFI’ ‘103857.LOFI’ ‘1147737.LOFI’ ‘1156133.LOFI’ ‘1163534.LOFI’ ‘1164433.LOFI’ ‘1185017.LOFI’ ‘1205438.LOFI’ ‘1270235.LOFI’ ‘1288533.LOFI’ ‘1312884.LOFI’ … CSV
1.0 compared with schreiber2017/ismir2017 (986 differences): ‘100066.LOFI’ ‘1017875.LOFI’ ‘1019315.LOFI’ ‘1034722.LOFI’ ‘10359.LOFI’ ‘1038248.LOFI’ ‘1054705.LOFI’ ‘1056047.LOFI’ ‘1059355.LOFI’ ‘1067950.LOFI’ ‘1072514.LOFI’ … CSV
1.0 compared with schreiber2017/mirex2017 (117 differences): ‘1034722.LOFI’ ‘1164433.LOFI’ ‘1185017.LOFI’ ‘1187324.LOFI’ ‘1267809.LOFI’ ‘1288533.LOFI’ ‘132143.LOFI’ ‘1334754.LOFI’ ‘1350891.LOFI’ ‘1397802.LOFI’ ‘1416128.LOFI’ … CSV
1.0 compared with schreiber2018/cnn (69 differences): ‘1164433.LOFI’ ‘1185017.LOFI’ ‘1187324.LOFI’ ‘1288533.LOFI’ ‘132143.LOFI’ ‘1397802.LOFI’ ‘1416128.LOFI’ ‘1426839.LOFI’ ‘1441223.LOFI’ ‘1478848.LOFI’ ‘1579295.LOFI’ … CSV
1.0 compared with schreiber2018/fcn (71 differences): ‘1164433.LOFI’ ‘1185017.LOFI’ ‘1187324.LOFI’ ‘132143.LOFI’ ‘1350891.LOFI’ ‘1397802.LOFI’ ‘1402876.LOFI’ ‘1416128.LOFI’ ‘1426839.LOFI’ ‘1428584.LOFI’ ‘1478848.LOFI’ … CSV
1.0 compared with schreiber2018/ismir2018 (94 differences): ‘1034722.LOFI’ ‘1147737.LOFI’ ‘1164433.LOFI’ ‘1185017.LOFI’ ‘1187324.LOFI’ ‘1205438.LOFI’ ‘1288533.LOFI’ ‘132143.LOFI’ ‘1334754.LOFI’ ‘1350891.LOFI’ ‘1397802.LOFI’ … CSV
None of the estimators estimated the following 18 items ‘correctly’ using Accuracy1: ‘1416128.LOFI’ ‘1426839.LOFI’ ‘1478848.LOFI’ ‘1579295.LOFI’ ‘1669212.LOFI’ ‘1895483.LOFI’ ‘2016942.LOFI’ ‘2090586.LOFI’ ‘297188.LOFI’ ‘297513.LOFI’ ‘298399.LOFI’ … CSV
Differing Items Accuracy2
Items with different tempo annotations (Accuracy2, 4% tolerance) in different versions:
1.0 compared with boeck2015/tempodetector2016_default (17 differences): ‘1164433.LOFI’ ‘1478848.LOFI’ ‘1579295.LOFI’ ‘1669212.LOFI’ ‘1895483.LOFI’ ‘297513.LOFI’ ‘298399.LOFI’ ‘298944.LOFI’ ‘299396.LOFI’ ‘3257500.LOFI’ ‘4123856.LOFI’ … CSV
1.0 compared with davies2009/mirex_qm_tempotracker (57 differences): ‘1147737.LOFI’ ‘1164433.LOFI’ ‘1277819.LOFI’ ‘1460099.LOFI’ ‘1478848.LOFI’ ‘1579295.LOFI’ ‘1669212.LOFI’ ‘1758017.LOFI’ ‘180831.LOFI’ ‘1857841.LOFI’ ‘1860990.LOFI’ … CSV
1.0 compared with percival2014/stem (10 differences): ‘1164433.LOFI’ ‘1478848.LOFI’ ‘1579295.LOFI’ ‘1669212.LOFI’ ‘1895483.LOFI’ ‘2016942.LOFI’ ‘297513.LOFI’ ‘298399.LOFI’ ‘3687603.LOFI’ ‘5338500.LOFI’ CSV
1.0 compared with schreiber2014/default (39 differences): ‘1156133.LOFI’ ‘1163534.LOFI’ ‘1164433.LOFI’ ‘1478848.LOFI’ ‘1579295.LOFI’ ‘1669212.LOFI’ ‘1895483.LOFI’ ‘2016942.LOFI’ ‘2090586.LOFI’ ‘297513.LOFI’ ‘297721.LOFI’ … CSV
1.0 compared with schreiber2017/ismir2017 (932 differences): ‘100066.LOFI’ ‘1017875.LOFI’ ‘1019315.LOFI’ ‘10359.LOFI’ ‘1038248.LOFI’ ‘1054705.LOFI’ ‘1056047.LOFI’ ‘1059355.LOFI’ ‘1067950.LOFI’ ‘1072514.LOFI’ ‘1077935.LOFI’ … CSV
1.0 compared with schreiber2017/mirex2017 (22 differences): ‘1164433.LOFI’ ‘1478848.LOFI’ ‘1579295.LOFI’ ‘1669212.LOFI’ ‘180831.LOFI’ ‘1895483.LOFI’ ‘2090586.LOFI’ ‘297513.LOFI’ ‘297620.LOFI’ ‘298399.LOFI’ ‘298944.LOFI’ … CSV
1.0 compared with schreiber2018/cnn (10 differences): ‘1164433.LOFI’ ‘1478848.LOFI’ ‘1579295.LOFI’ ‘1669212.LOFI’ ‘1895483.LOFI’ ‘297513.LOFI’ ‘298399.LOFI’ ‘299396.LOFI’ ‘3687603.LOFI’ ‘6221323.LOFI’ CSV
1.0 compared with schreiber2018/fcn (10 differences): ‘1164433.LOFI’ ‘1478848.LOFI’ ‘1579295.LOFI’ ‘1669212.LOFI’ ‘1895483.LOFI’ ‘2016942.LOFI’ ‘297513.LOFI’ ‘298399.LOFI’ ‘299396.LOFI’ ‘6221323.LOFI’ CSV
1.0 compared with schreiber2018/ismir2018 (10 differences): ‘1164433.LOFI’ ‘1478848.LOFI’ ‘1579295.LOFI’ ‘1669212.LOFI’ ‘1895483.LOFI’ ‘2016942.LOFI’ ‘297513.LOFI’ ‘298399.LOFI’ ‘299396.LOFI’ ‘6221323.LOFI’ CSV
None of the estimators estimated the following 6 items ‘correctly’ using Accuracy2: ‘1478848.LOFI’ ‘1579295.LOFI’ ‘1669212.LOFI’ ‘1895483.LOFI’ ‘297513.LOFI’ ‘298399.LOFI’ CSV
Significance of Differences
| Estimator | boeck2015/tempodetector2016_default | davies2009/mirex_qm_tempotracker | percival2014/stem | schreiber2014/default | schreiber2017/ismir2017 | schreiber2017/mirex2017 | schreiber2018/cnn | schreiber2018/fcn | schreiber2018/ismir2018 |
|---|---|---|---|---|---|---|---|---|---|
| boeck2015/tempodetector2016_default | 1.0000 | 0.0000 | 0.0238 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 |
| davies2009/mirex_qm_tempotracker | 0.0000 | 1.0000 | 0.0000 | 0.7495 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 |
| percival2014/stem | 0.0238 | 0.0000 | 1.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 |
| schreiber2014/default | 0.0000 | 0.7495 | 0.0000 | 1.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 |
| schreiber2017/ismir2017 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 1.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 |
| schreiber2017/mirex2017 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 1.0000 | 0.0000 | 0.0000 | 0.0067 |
| schreiber2018/cnn | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 1.0000 | 0.8776 | 0.0002 |
| schreiber2018/fcn | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.8776 | 1.0000 | 0.0011 |
| schreiber2018/ismir2018 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0067 | 0.0002 | 0.0011 | 1.0000 |
Table 4: McNemar p-values, using reference annotations 1.0 as groundtruth with Accuracy1 [Gouyon2006]. H0: both estimators disagree with the groundtruth to the same amount. If p<=ɑ, reject H0, i.e. we have a significant difference in the disagreement with the groundtruth. In the table, p-values<0.05 are set in bold.
| Estimator | boeck2015/tempodetector2016_default | davies2009/mirex_qm_tempotracker | percival2014/stem | schreiber2014/default | schreiber2017/ismir2017 | schreiber2017/mirex2017 | schreiber2018/cnn | schreiber2018/fcn | schreiber2018/ismir2018 |
|---|---|---|---|---|---|---|---|---|---|
| boeck2015/tempodetector2016_default | 1.0000 | 0.0000 | 0.0923 | 0.0001 | 0.0000 | 0.3018 | 0.0391 | 0.0391 | 0.0391 |
| davies2009/mirex_qm_tempotracker | 0.0000 | 1.0000 | 0.0000 | 0.0385 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 |
| percival2014/stem | 0.0923 | 0.0000 | 1.0000 | 0.0000 | 0.0000 | 0.0042 | 1.0000 | 1.0000 | 1.0000 |
| schreiber2014/default | 0.0001 | 0.0385 | 0.0000 | 1.0000 | 0.0000 | 0.0005 | 0.0000 | 0.0000 | 0.0000 |
| schreiber2017/ismir2017 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 1.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 |
| schreiber2017/mirex2017 | 0.3018 | 0.0000 | 0.0042 | 0.0005 | 0.0000 | 1.0000 | 0.0018 | 0.0042 | 0.0042 |
| schreiber2018/cnn | 0.0391 | 0.0000 | 1.0000 | 0.0000 | 0.0000 | 0.0018 | 1.0000 | 1.0000 | 1.0000 |
| schreiber2018/fcn | 0.0391 | 0.0000 | 1.0000 | 0.0000 | 0.0000 | 0.0042 | 1.0000 | 1.0000 | 1.0000 |
| schreiber2018/ismir2018 | 0.0391 | 0.0000 | 1.0000 | 0.0000 | 0.0000 | 0.0042 | 1.0000 | 1.0000 | 1.0000 |
Table 5: McNemar p-values, using reference annotations 1.0 as groundtruth with Accuracy2 [Gouyon2006]. H0: both estimators disagree with the groundtruth to the same amount. If p<=ɑ, reject H0, i.e. we have a significant difference in the disagreement with the groundtruth. In the table, p-values<0.05 are set in bold.
Accuracy1 on Tempo-Subsets
How well does an estimator perform, when only taking a subset of the reference annotations into account? The graphs show mean Accuracy1 for reference subsets with tempi in [T-10,T+10] BPM. Note that the graphs do not show confidence intervals and that some values may be based on very few estimates.
Accuracy1 on Tempo-Subsets for 1.0
Figure 6: Mean Accuracy1 for estimates compared to version 1.0 for tempo intervals around T.
CSV JSON LATEX PICKLE SVG PDF PNG
{kind=link}
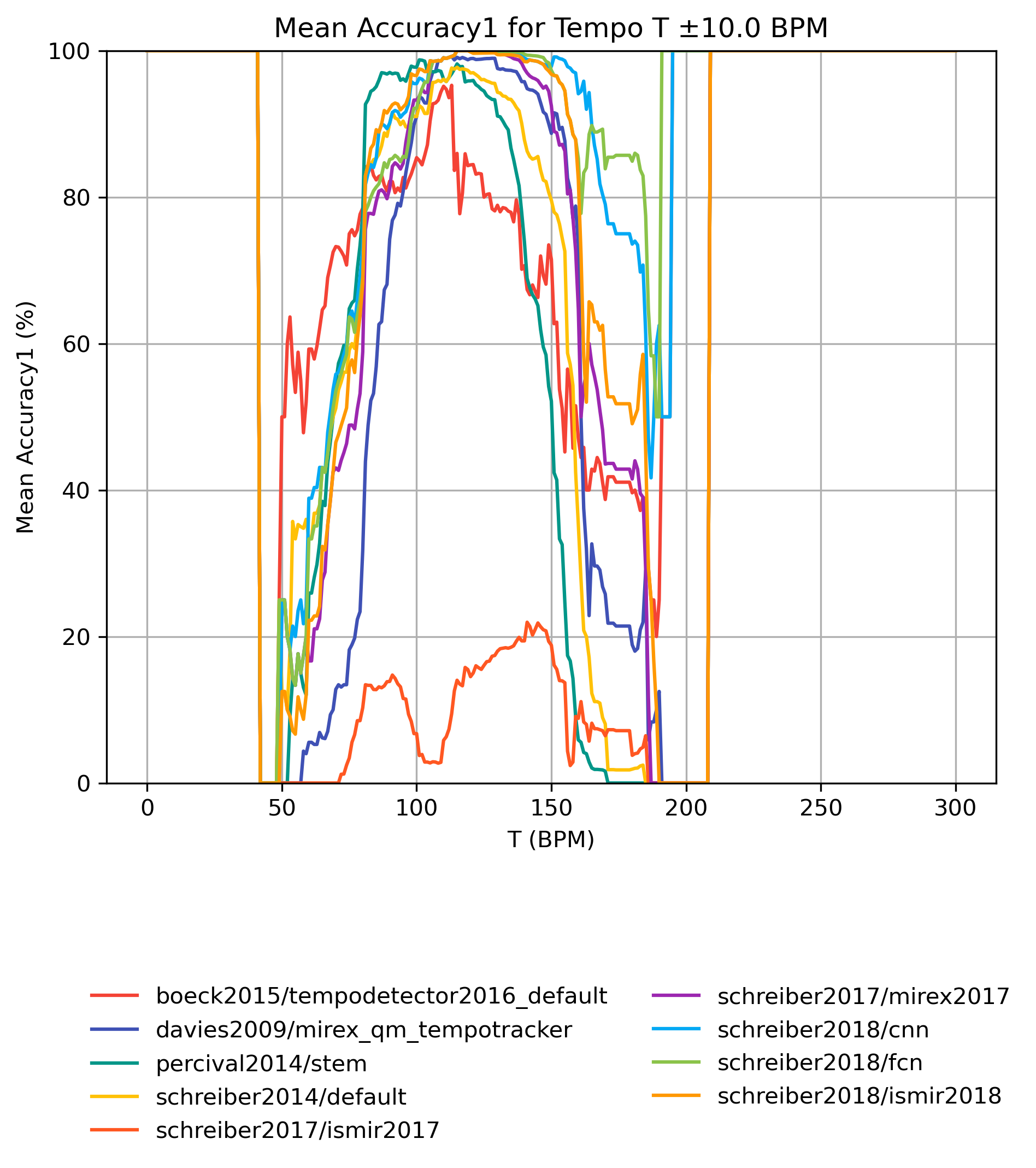{kind=link}
Accuracy2 on Tempo-Subsets
How well does an estimator perform, when only taking a subset of the reference annotations into account? The graphs show mean Accuracy2 for reference subsets with tempi in [T-10,T+10] BPM. Note that the graphs do not show confidence intervals and that some values may be based on very few estimates.
Accuracy2 on Tempo-Subsets for 1.0
Figure 7: Mean Accuracy2 for estimates compared to version 1.0 for tempo intervals around T.
CSV JSON LATEX PICKLE SVG PDF PNG
{kind=link}
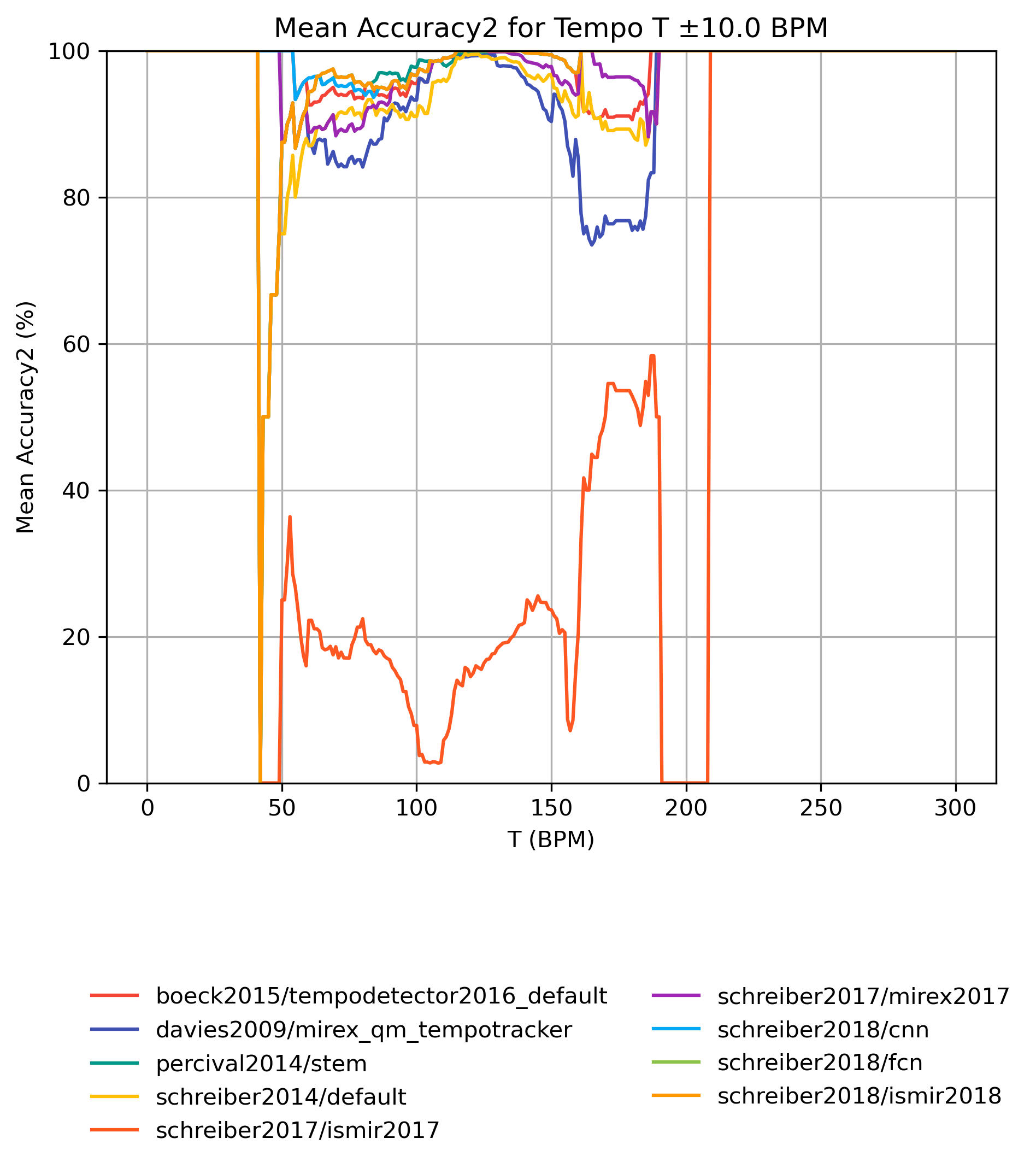{kind=link}
Estimated Accuracy1 for Tempo
When fitting a generalized additive model (GAM) to Accuracy1-values and a ground truth, what Accuracy1 can we expect with confidence?
Estimated Accuracy1 for Tempo for 1.0
Predictions of GAMs trained on Accuracy1 for estimates for reference 1.0.
Figure 8: Accuracy1 predictions of a generalized additive model (GAM) fit to Accuracy1 results for 1.0. The 95% confidence interval around the prediction is shaded in gray.
CSV JSON LATEX PICKLE SVG PDF PNG
{kind=link}
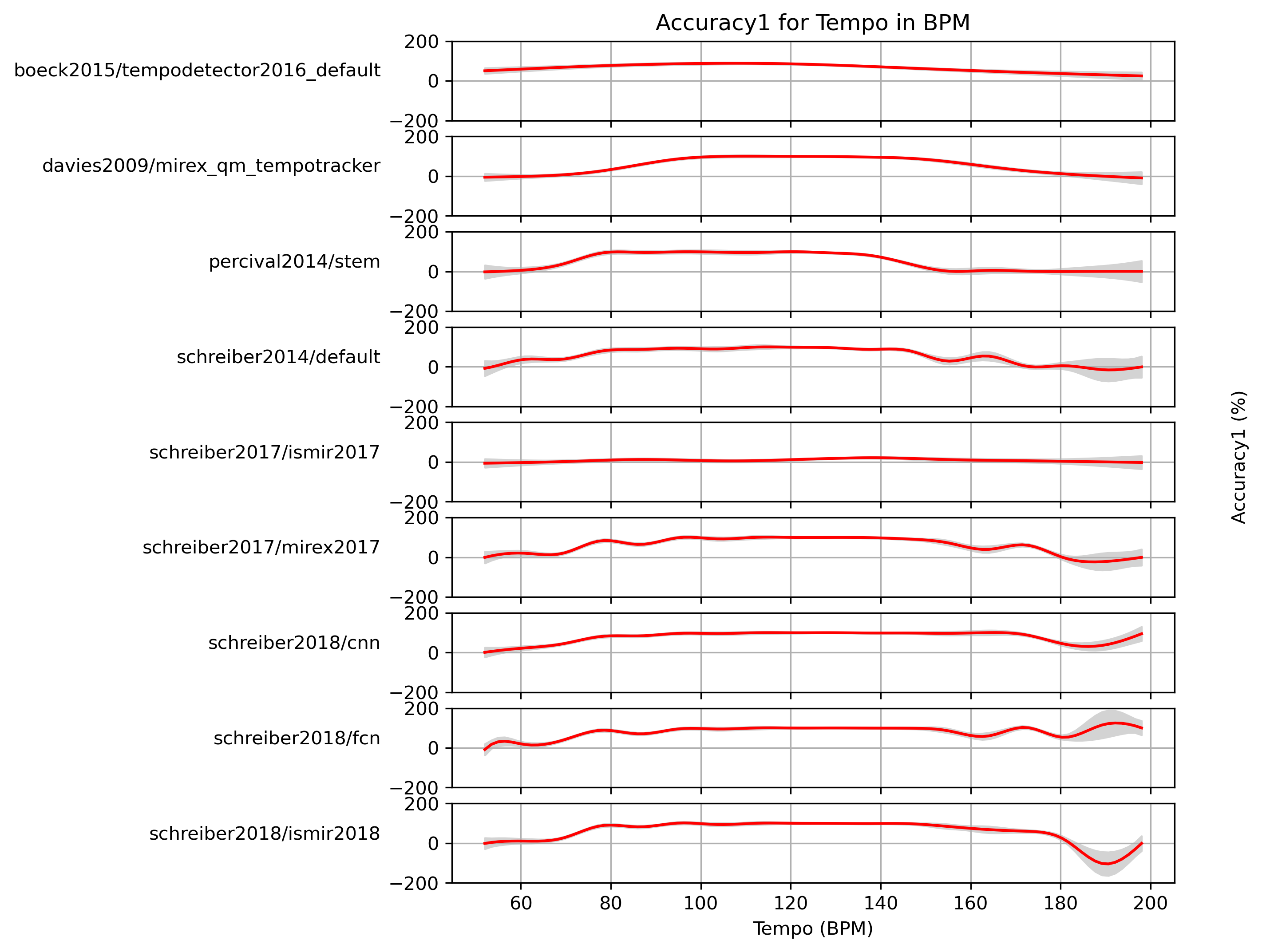{kind=link}
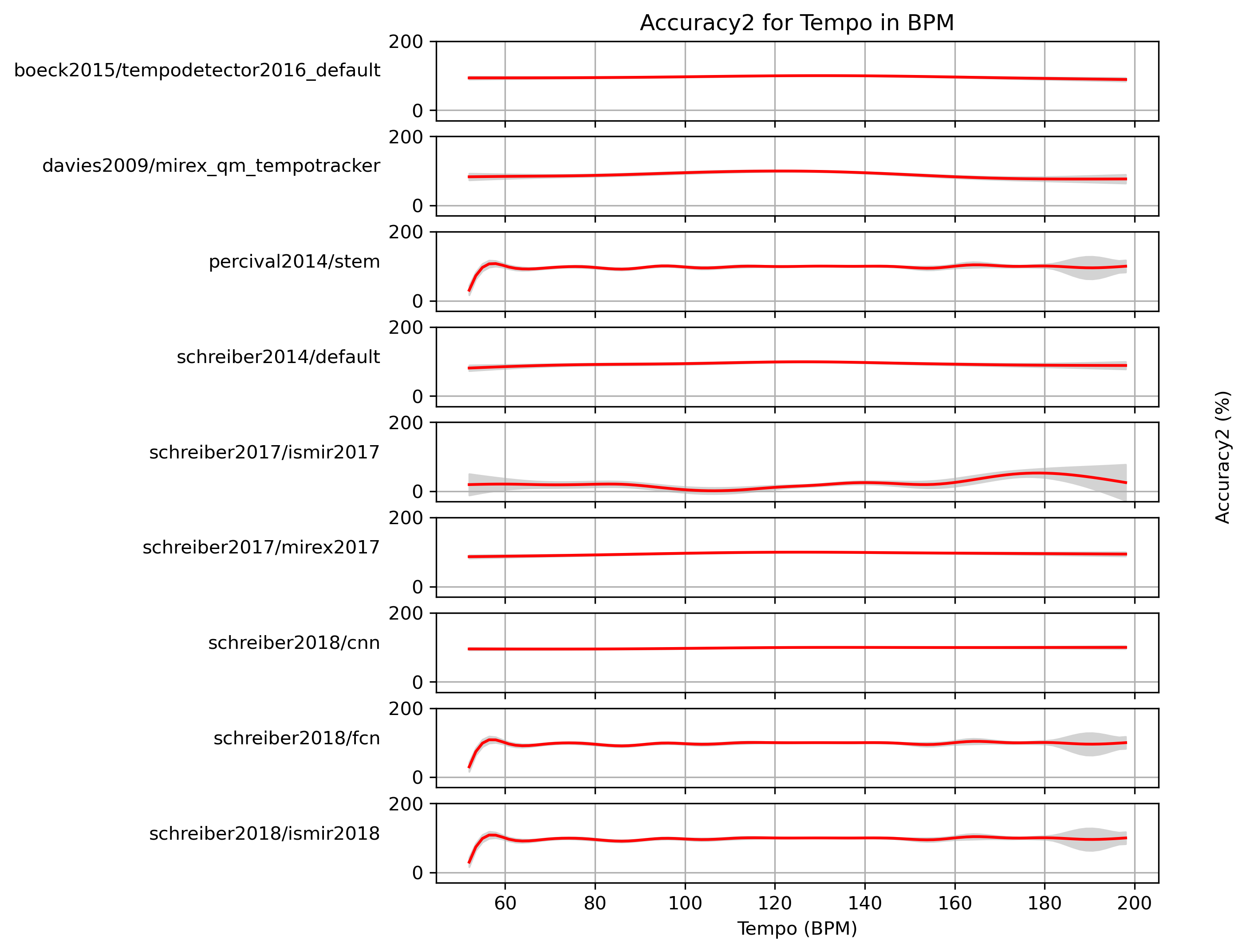
Estimated Accuracy2 for Tempo
When fitting a generalized additive model (GAM) to Accuracy2-values and a ground truth, what Accuracy2 can we expect with confidence?
Estimated Accuracy2 for Tempo for 1.0
Predictions of GAMs trained on Accuracy2 for estimates for reference 1.0.
Figure 9: Accuracy2 predictions of a generalized additive model (GAM) fit to Accuracy2 results for 1.0. The 95% confidence interval around the prediction is shaded in gray.
CSV JSON LATEX PICKLE SVG PDF PNG
{kind=link}
{kind=link}
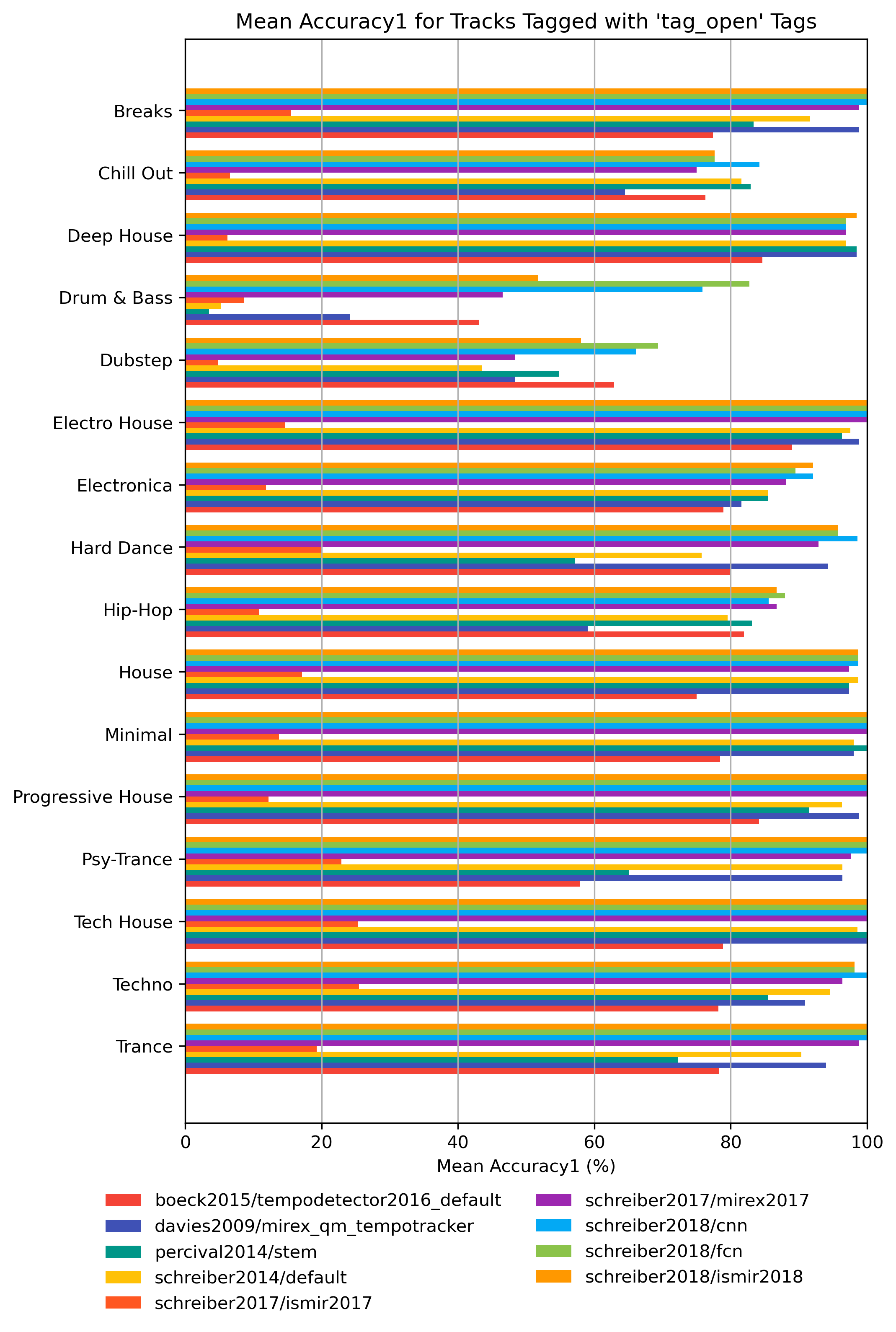
Accuracy1 for ‘tag_open’ Tags
How well does an estimator perform, when only taking tracks into account that are tagged with some kind of label? Note that some values may be based on very few estimates.
Accuracy1 for ‘tag_open’ Tags for 1.0
Figure 10: Mean Accuracy1 of estimates compared to version 1.0 depending on tag from namespace ‘tag_open’.
CSV JSON LATEX PICKLE SVG PDF PNG
{kind=link}
{kind=link}
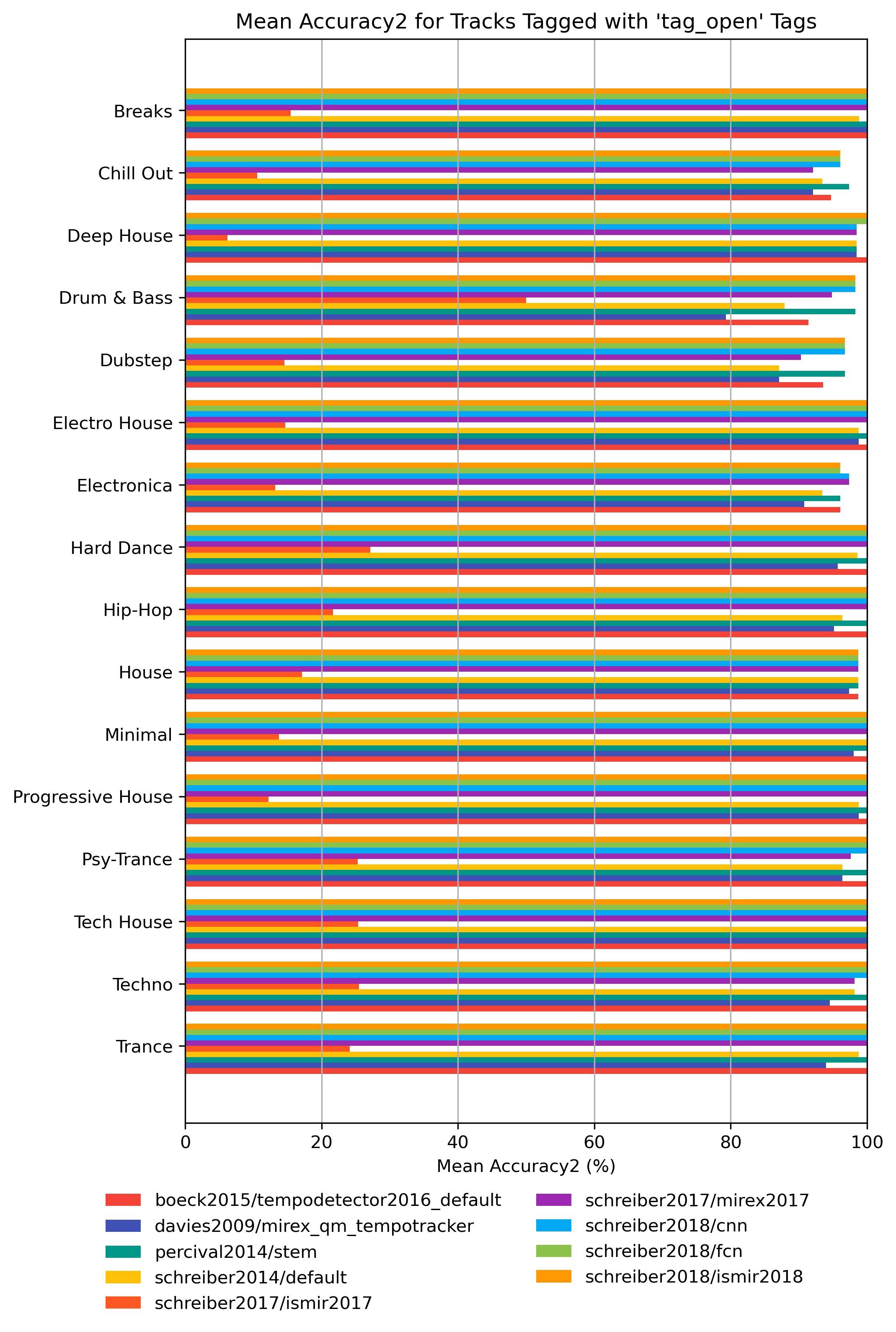
Accuracy2 for ‘tag_open’ Tags
How well does an estimator perform, when only taking tracks into account that are tagged with some kind of label? Note that some values may be based on very few estimates.
Accuracy2 for ‘tag_open’ Tags for 1.0
Figure 11: Mean Accuracy2 of estimates compared to version 1.0 depending on tag from namespace ‘tag_open’.
CSV JSON LATEX PICKLE SVG PDF PNG
{kind=link}
{kind=link}
OE1 and OE2
OE1 is defined as octave error between an estimate E and a reference value R.This means that the most common errors—by a factor of 2 or ½—have the same magnitude, namely 1: OE2(E) = log2(E/R).
OE2 is the signed OE1 corresponding to the minimum absolute OE1 allowing the octaveerrors 2, 3, 1/2, and 1/3: OE2(E) = arg minx(|x|) with x ∈ {OE1(E), OE1(2E), OE1(3E), OE1(½E), OE1(⅓E)}
Mean OE1/OE2 Results for 1.0
| Estimator | OE1_MEAN | OE1_STDEV | OE2_MEAN | OE2_STDEV |
|---|---|---|---|---|
| schreiber2018/cnn | 0.0238 | 0.2316 | -0.0009 | 0.0293 |
| schreiber2018/fcn | 0.0340 | 0.2323 | -0.0020 | 0.0294 |
| schreiber2018/ismir2018 | 0.0140 | 0.2723 | -0.0025 | 0.0321 |
| schreiber2017/mirex2017 | 0.0094 | 0.2950 | -0.0044 | 0.0505 |
| davies2009/mirex_qm_tempotracker | 0.0518 | 0.3461 | 0.0318 | 0.0828 |
| schreiber2014/default | -0.0624 | 0.3597 | -0.0079 | 0.0679 |
| percival2014/stem | -0.1294 | 0.4288 | -0.0014 | 0.0304 |
| boeck2015/tempodetector2016_default | -0.1942 | 0.4748 | -0.0053 | 0.0439 |
| schreiber2017/ismir2017 | -0.1258 | 0.4772 | 0.0759 | 0.2637 |
Table 6: Mean OE1/OE2 for estimates compared to version 1.0 ordered by standard deviation.
Raw data OE1: CSV JSON LATEX PICKLE
Raw data OE2: CSV JSON LATEX PICKLE
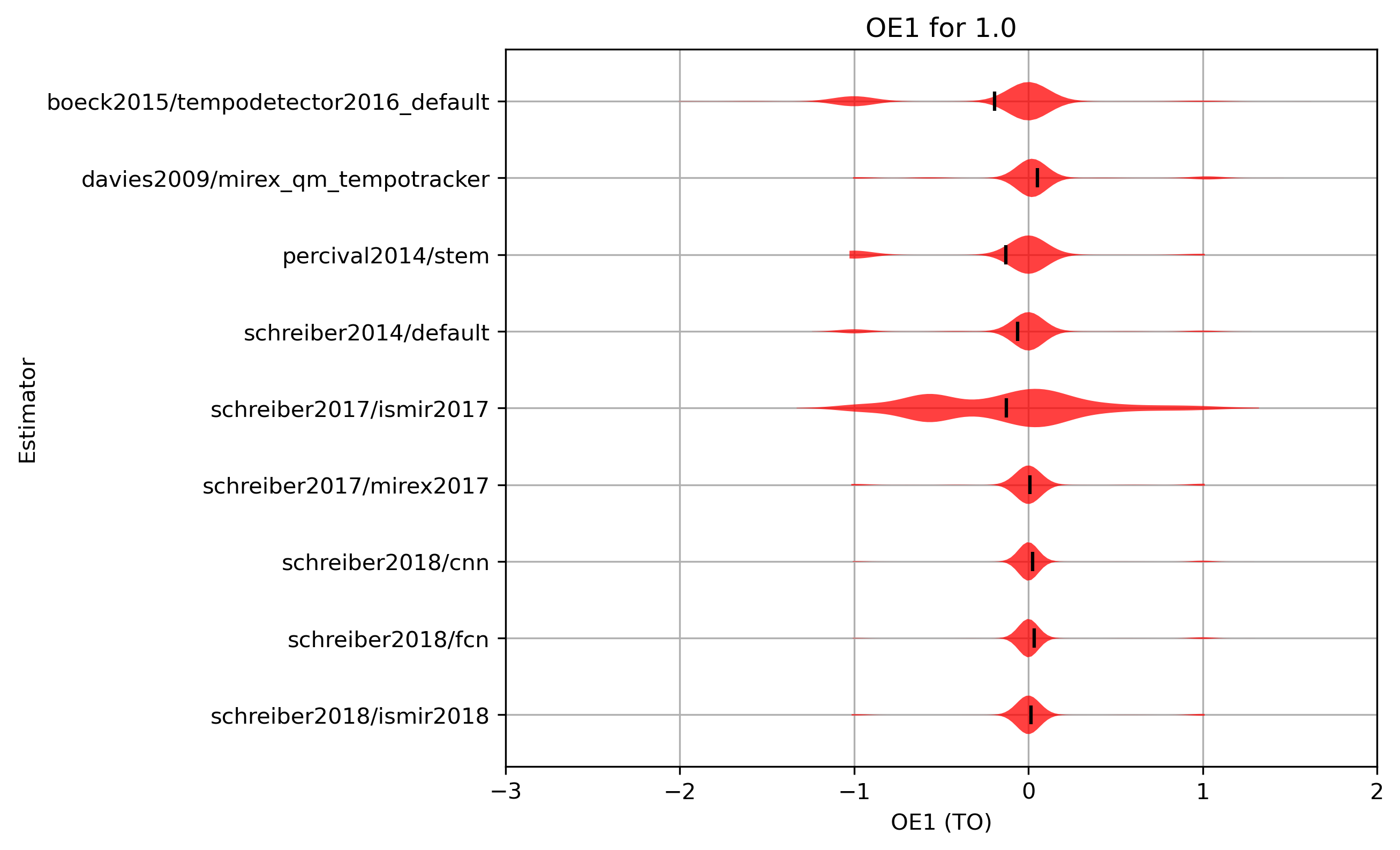
OE1 distribution for 1.0
Figure 12: OE1 for estimates compared to version 1.0. Shown are the mean OE1 and an empirical distribution of the sample, using kernel density estimation (KDE).
CSV JSON LATEX PICKLE SVG PDF PNG
{kind=link}
{kind=link}
OE2 distribution for 1.0
Figure 13: OE2 for estimates compared to version 1.0. Shown are the mean OE2 and an empirical distribution of the sample, using kernel density estimation (KDE).
CSV JSON LATEX PICKLE SVG PDF PNG
{kind=link}
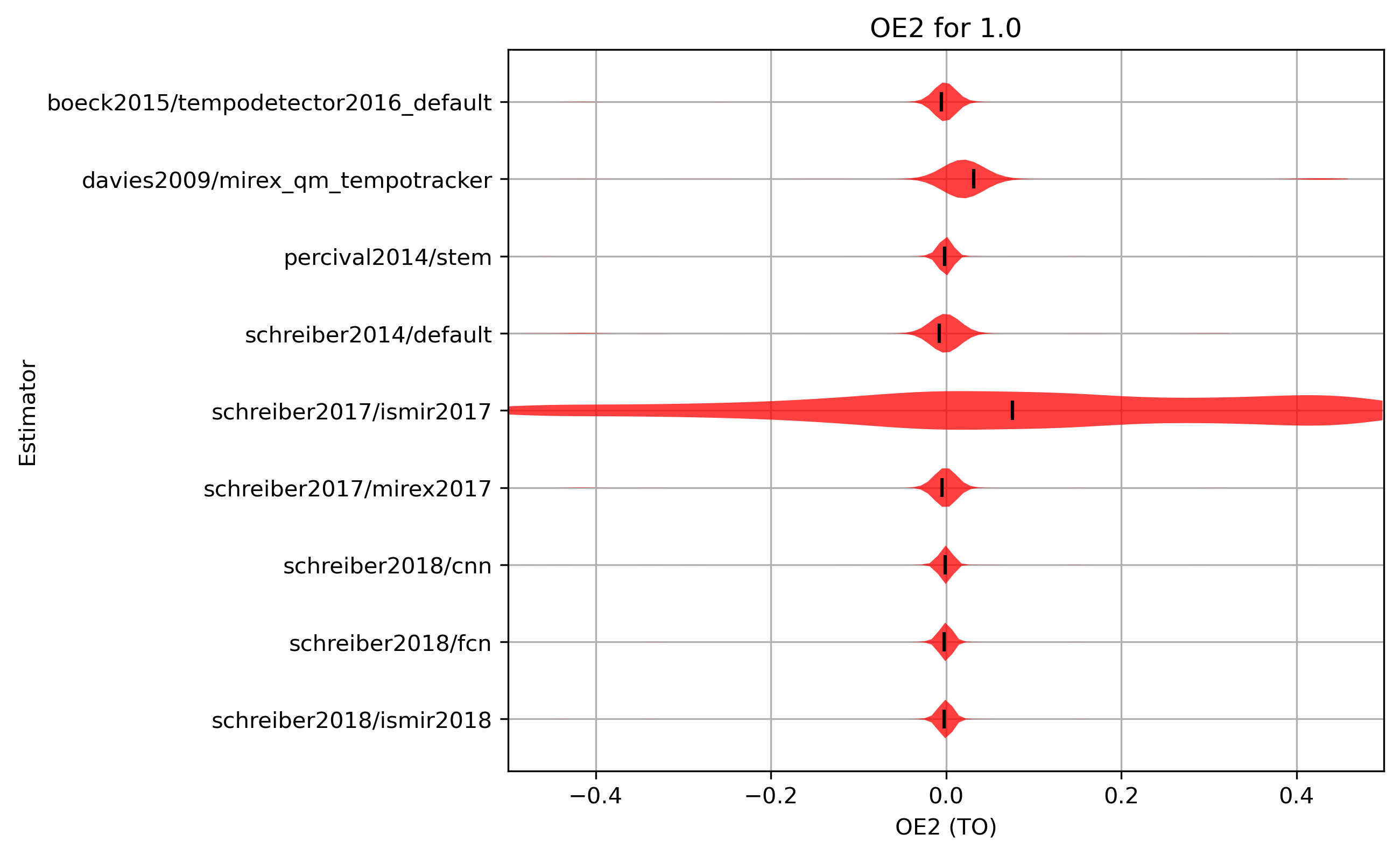{kind=link}
Significance of Differences
| Estimator | boeck2015/tempodetector2016_default | davies2009/mirex_qm_tempotracker | percival2014/stem | schreiber2014/default | schreiber2017/ismir2017 | schreiber2017/mirex2017 | schreiber2018/cnn | schreiber2018/fcn | schreiber2018/ismir2018 |
|---|---|---|---|---|---|---|---|---|---|
| boeck2015/tempodetector2016_default | 1.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0001 | 0.0000 | 0.0000 | 0.0000 | 0.0000 |
| davies2009/mirex_qm_tempotracker | 0.0000 | 1.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0012 | 0.0476 | 0.0000 |
| percival2014/stem | 0.0000 | 0.0000 | 1.0000 | 0.0000 | 0.8002 | 0.0000 | 0.0000 | 0.0000 | 0.0000 |
| schreiber2014/default | 0.0000 | 0.0000 | 0.0000 | 1.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 |
| schreiber2017/ismir2017 | 0.0001 | 0.0000 | 0.8002 | 0.0000 | 1.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 |
| schreiber2017/mirex2017 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 1.0000 | 0.0441 | 0.0007 | 0.5063 |
| schreiber2018/cnn | 0.0000 | 0.0012 | 0.0000 | 0.0000 | 0.0000 | 0.0441 | 1.0000 | 0.0808 | 0.0990 |
| schreiber2018/fcn | 0.0000 | 0.0476 | 0.0000 | 0.0000 | 0.0000 | 0.0007 | 0.0808 | 1.0000 | 0.0009 |
| schreiber2018/ismir2018 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.5063 | 0.0990 | 0.0009 | 1.0000 |
Table 7: Paired t-test p-values, using reference annotations 1.0 as groundtruth with OE1. H0: the true mean difference between paired samples is zero. If p<=ɑ, reject H0, i.e. we have a significant difference between estimates from the two algorithms. In the table, p-values<0.05 are set in bold.
| Estimator | boeck2015/tempodetector2016_default | davies2009/mirex_qm_tempotracker | percival2014/stem | schreiber2014/default | schreiber2017/ismir2017 | schreiber2017/mirex2017 | schreiber2018/cnn | schreiber2018/fcn | schreiber2018/ismir2018 |
|---|---|---|---|---|---|---|---|---|---|
| boeck2015/tempodetector2016_default | 1.0000 | 0.0000 | 0.0058 | 0.1842 | 0.0000 | 0.5938 | 0.0004 | 0.0070 | 0.0218 |
| davies2009/mirex_qm_tempotracker | 0.0000 | 1.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 |
| percival2014/stem | 0.0058 | 0.0000 | 1.0000 | 0.0012 | 0.0000 | 0.0786 | 0.6474 | 0.5071 | 0.1977 |
| schreiber2014/default | 0.1842 | 0.0000 | 0.0012 | 1.0000 | 0.0000 | 0.0414 | 0.0005 | 0.0015 | 0.0035 |
| schreiber2017/ismir2017 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 1.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 |
| schreiber2017/mirex2017 | 0.5938 | 0.0000 | 0.0786 | 0.0414 | 0.0000 | 1.0000 | 0.0066 | 0.0738 | 0.1731 |
| schreiber2018/cnn | 0.0004 | 0.0000 | 0.6474 | 0.0005 | 0.0000 | 0.0066 | 1.0000 | 0.2010 | 0.1021 |
| schreiber2018/fcn | 0.0070 | 0.0000 | 0.5071 | 0.0015 | 0.0000 | 0.0738 | 0.2010 | 1.0000 | 0.1530 |
| schreiber2018/ismir2018 | 0.0218 | 0.0000 | 0.1977 | 0.0035 | 0.0000 | 0.1731 | 0.1021 | 0.1530 | 1.0000 |
Table 8: Paired t-test p-values, using reference annotations 1.0 as groundtruth with OE2. H0: the true mean difference between paired samples is zero. If p<=ɑ, reject H0, i.e. we have a significant difference between estimates from the two algorithms. In the table, p-values<0.05 are set in bold.
OE1 on Tempo-Subsets
How well does an estimator perform, when only taking a subset of the reference annotations into account? The graphs show mean OE1 for reference subsets with tempi in [T-10,T+10] BPM. Note that the graphs do not show confidence intervals and that some values may be based on very few estimates.
OE1 on Tempo-Subsets for 1.0
Figure 14: Mean OE1 for estimates compared to version 1.0 for tempo intervals around T.
CSV JSON LATEX PICKLE SVG PDF PNG
{kind=link}
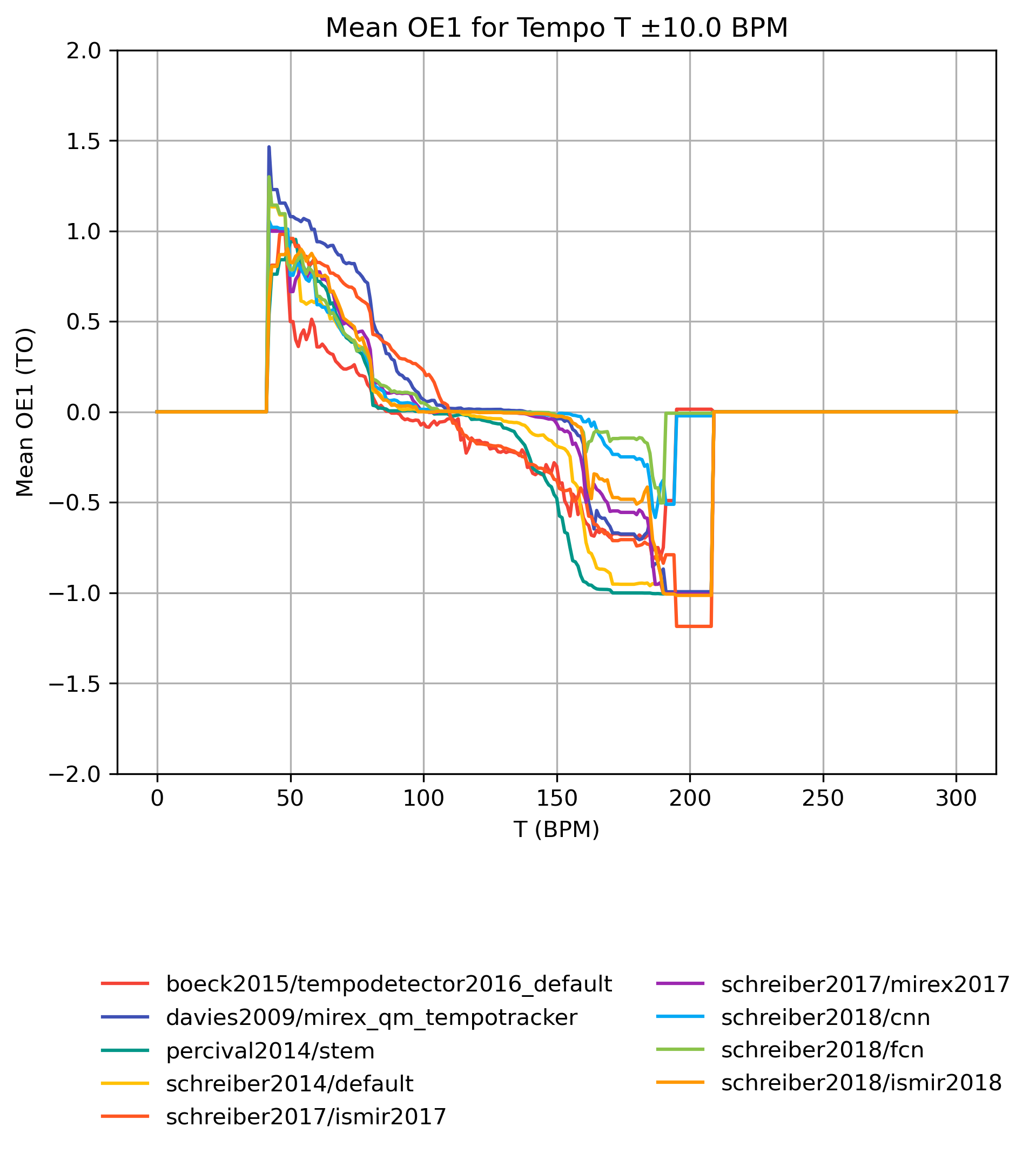{kind=link}
OE2 on Tempo-Subsets
How well does an estimator perform, when only taking a subset of the reference annotations into account? The graphs show mean OE2 for reference subsets with tempi in [T-10,T+10] BPM. Note that the graphs do not show confidence intervals and that some values may be based on very few estimates.
OE2 on Tempo-Subsets for 1.0
Figure 15: Mean OE2 for estimates compared to version 1.0 for tempo intervals around T.
CSV JSON LATEX PICKLE SVG PDF PNG
{kind=link}
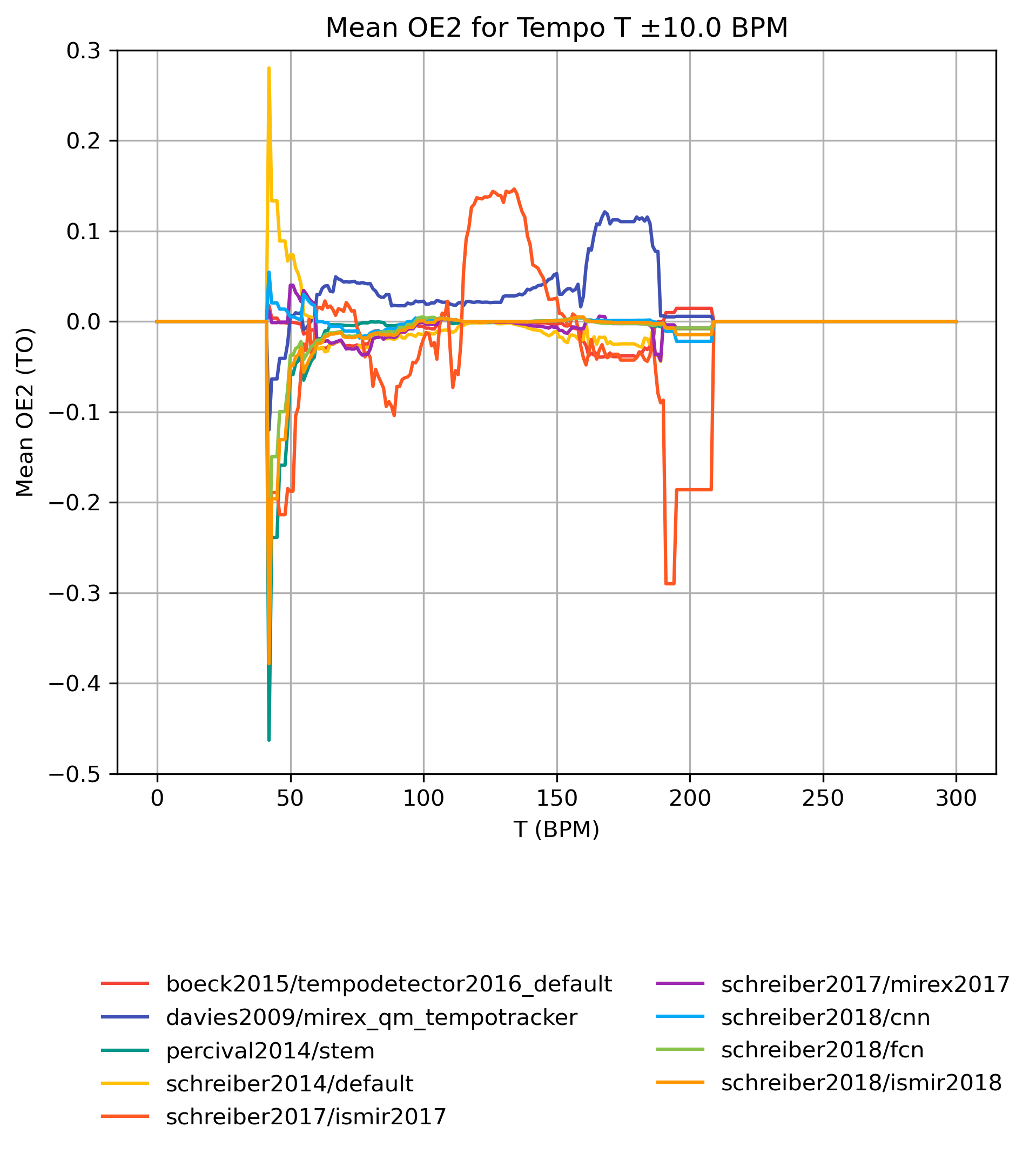{kind=link}
Estimated OE1 for Tempo
When fitting a generalized additive model (GAM) to OE1-values and a ground truth, what OE1 can we expect with confidence?
Estimated OE1 for Tempo for 1.0
Predictions of GAMs trained on OE1 for estimates for reference 1.0.
Figure 16: OE1 predictions of a generalized additive model (GAM) fit to OE1 results for 1.0. The 95% confidence interval around the prediction is shaded in gray.
CSV JSON LATEX PICKLE SVG PDF PNG
{kind=link}
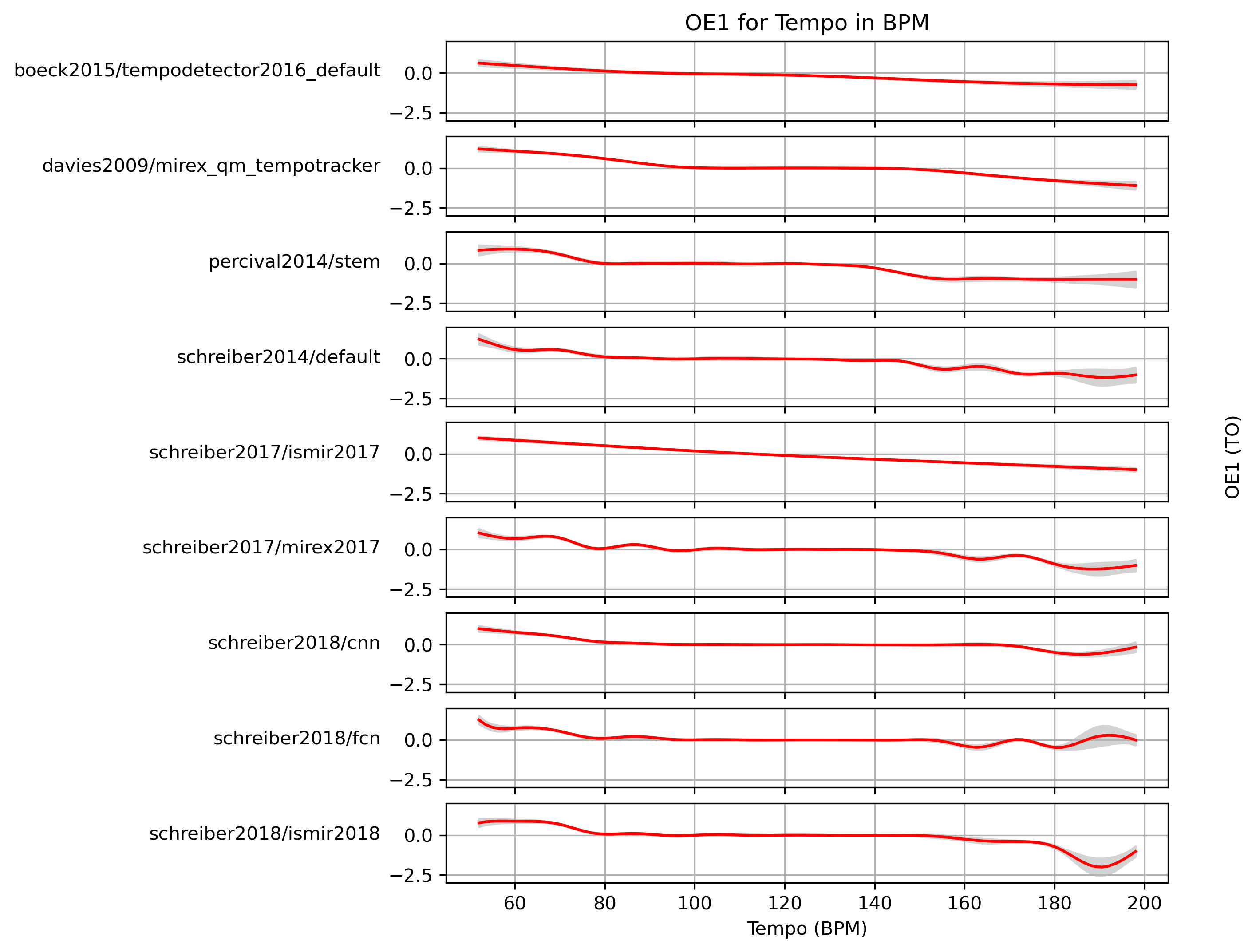{kind=link}
Estimated OE2 for Tempo
When fitting a generalized additive model (GAM) to OE2-values and a ground truth, what OE2 can we expect with confidence?
Estimated OE2 for Tempo for 1.0
Predictions of GAMs trained on OE2 for estimates for reference 1.0.
Figure 17: OE2 predictions of a generalized additive model (GAM) fit to OE2 results for 1.0. The 95% confidence interval around the prediction is shaded in gray.
CSV JSON LATEX PICKLE SVG PDF PNG
{kind=link}
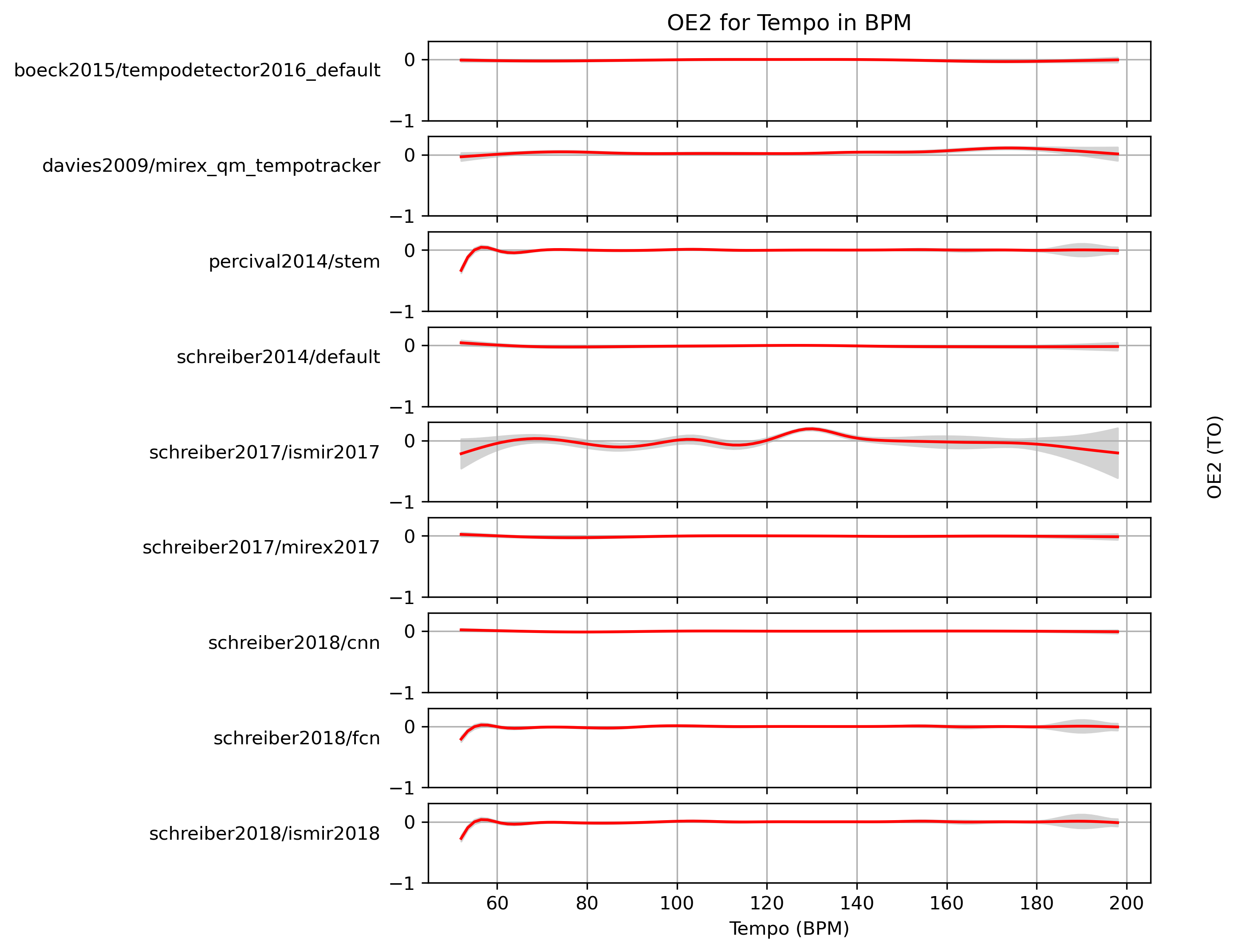{kind=link}
OE1 for ‘tag_open’ Tags
How well does an estimator perform, when only taking tracks into account that are tagged with some kind of label? Note that some values may be based on very few estimates.
OE1 for ‘tag_open’ Tags for 1.0
Figure 18: OE1 of estimates compared to version 1.0 depending on tag from namespace ‘tag_open’.
{kind=link}
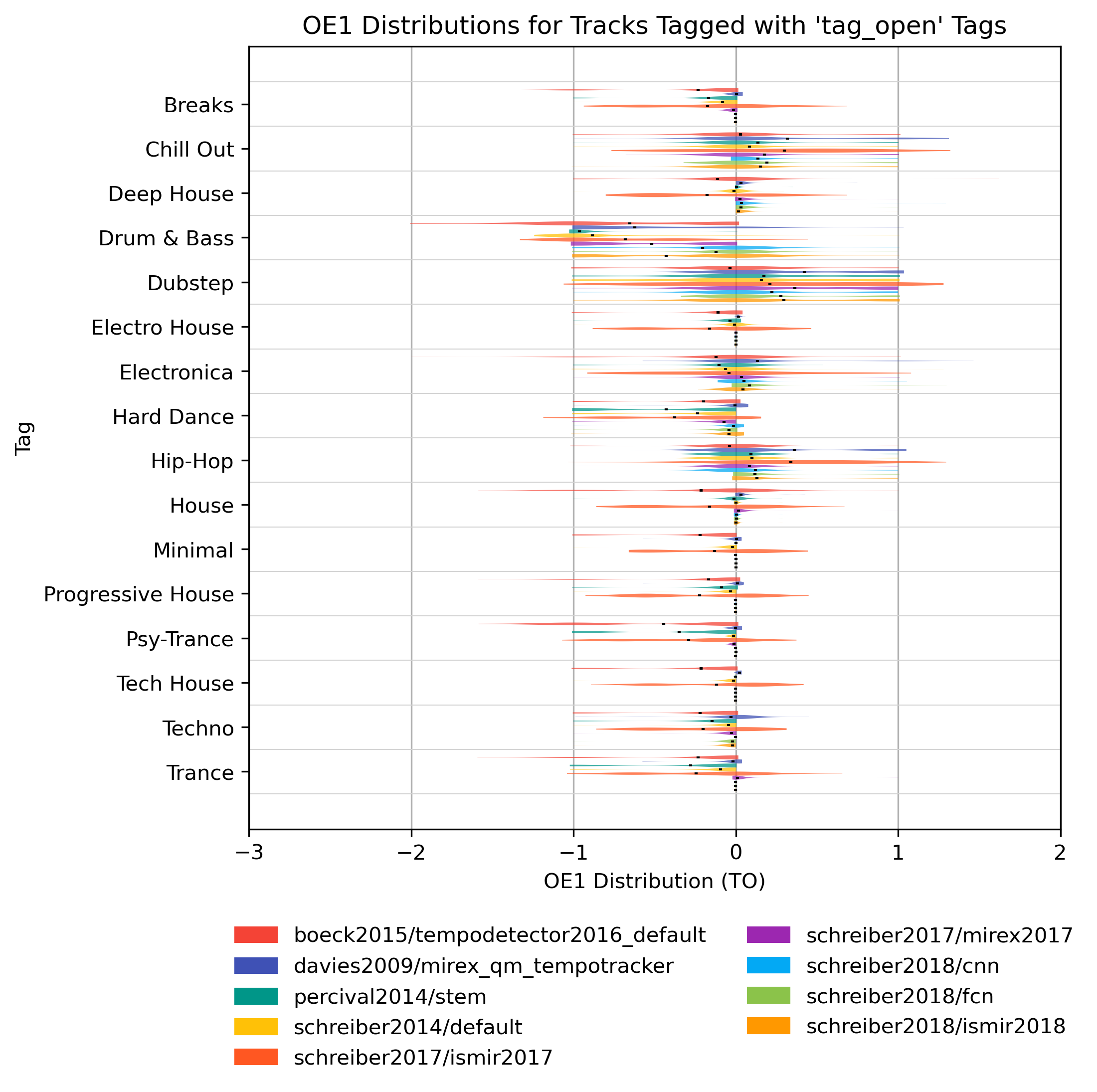{kind=link}
OE2 for ‘tag_open’ Tags
How well does an estimator perform, when only taking tracks into account that are tagged with some kind of label? Note that some values may be based on very few estimates.
OE2 for ‘tag_open’ Tags for 1.0
Figure 19: OE2 of estimates compared to version 1.0 depending on tag from namespace ‘tag_open’.
{kind=link}
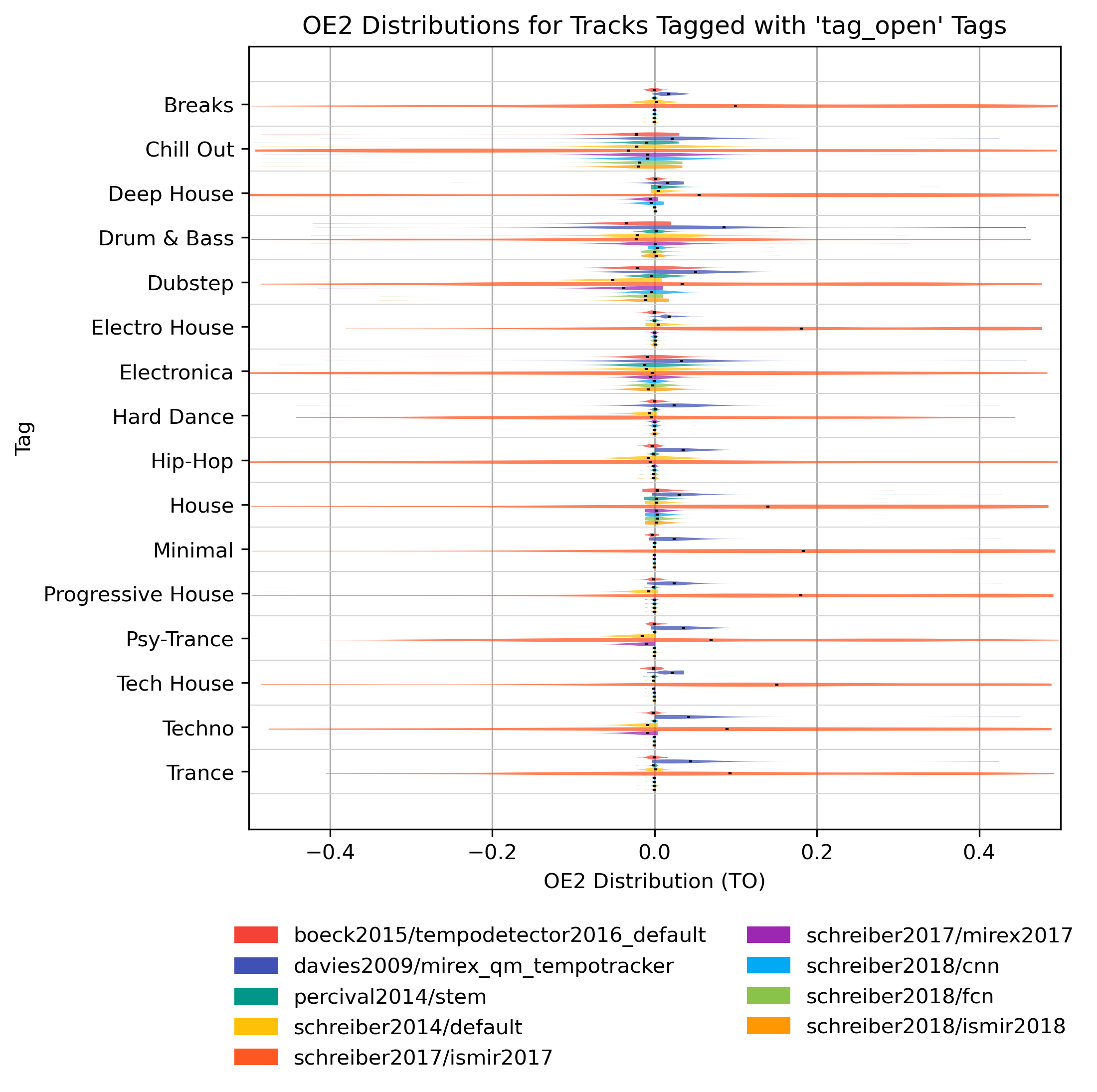{kind=link}
AOE1 and AOE2
AOE1 is defined as absolute octave error between an estimate and a reference value: AOE1(E) = |log2(E/R)|.
AOE2 is the minimum of AOE1 allowing the octave errors 2, 3, 1/2, and 1/3: AOE2(E) = min(AOE1(E), AOE1(2E), AOE1(3E), AOE1(½E), AOE1(⅓E)).
Mean AOE1/AOE2 Results for 1.0
| Estimator | AOE1_MEAN | AOE1_STDEV | AOE2_MEAN | AOE2_STDEV |
|---|---|---|---|---|
| schreiber2018/cnn | 0.0565 | 0.2259 | 0.0038 | 0.0290 |
| schreiber2018/fcn | 0.0577 | 0.2275 | 0.0040 | 0.0292 |
| schreiber2018/ismir2018 | 0.0773 | 0.2615 | 0.0042 | 0.0320 |
| schreiber2017/mirex2017 | 0.0927 | 0.2802 | 0.0083 | 0.0500 |
| schreiber2014/default | 0.1409 | 0.3368 | 0.0137 | 0.0670 |
| davies2009/mirex_qm_tempotracker | 0.1472 | 0.3175 | 0.0373 | 0.0805 |
| percival2014/stem | 0.2041 | 0.3987 | 0.0050 | 0.0301 |
| boeck2015/tempodetector2016_default | 0.2521 | 0.4467 | 0.0106 | 0.0429 |
| schreiber2017/ismir2017 | 0.3862 | 0.3072 | 0.2249 | 0.1572 |
Table 9: Mean AOE1/AOE2 for estimates compared to version 1.0 ordered by mean.
Raw data AOE1: CSV JSON LATEX PICKLE
Raw data AOE2: CSV JSON LATEX PICKLE
AOE1 distribution for 1.0
Figure 20: AOE1 for estimates compared to version 1.0. Shown are the mean AOE1 and an empirical distribution of the sample, using kernel density estimation (KDE).
CSV JSON LATEX PICKLE SVG PDF PNG
{kind=link}
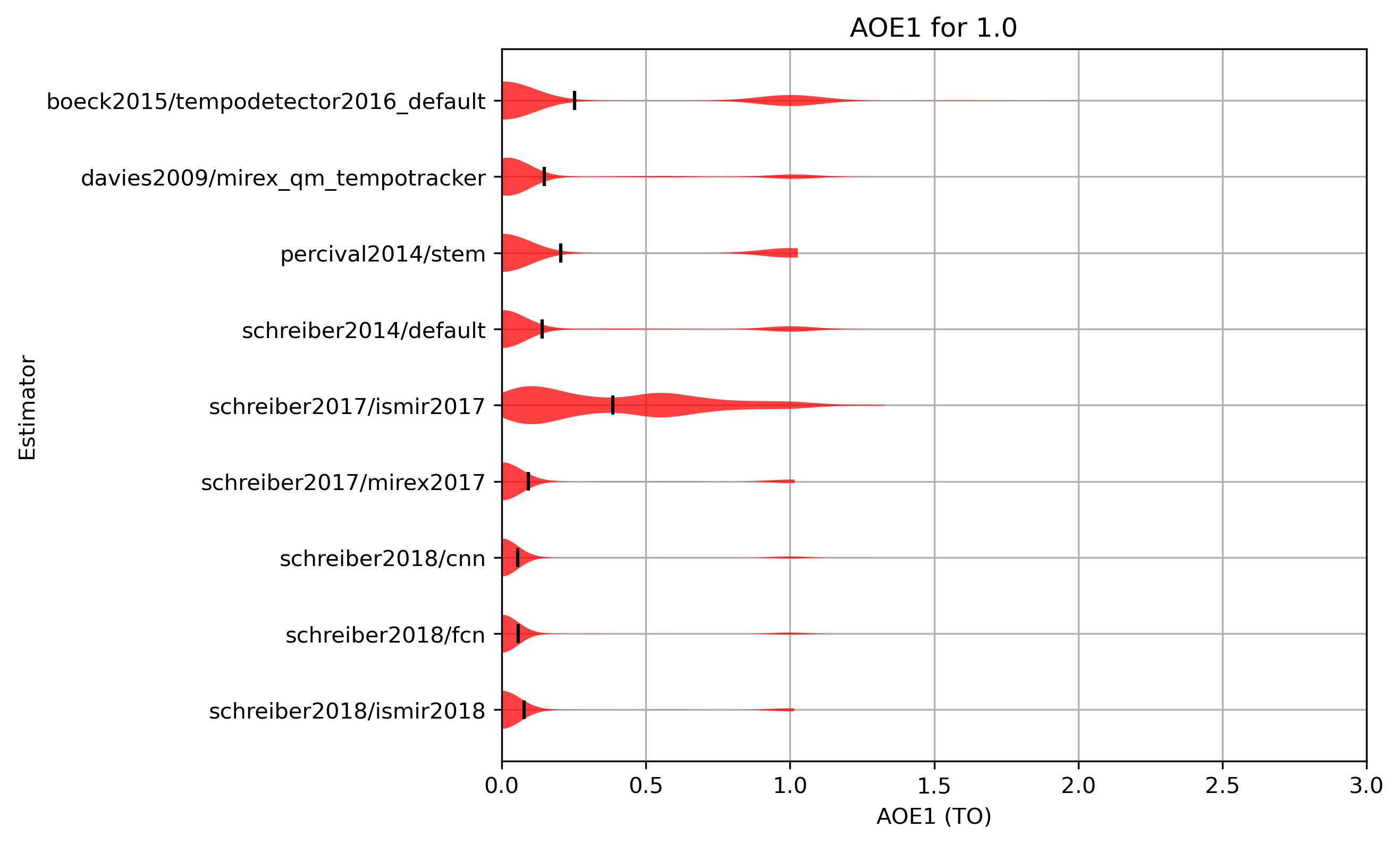{kind=link}
AOE2 distribution for 1.0
Figure 21: AOE2 for estimates compared to version 1.0. Shown are the mean AOE2 and an empirical distribution of the sample, using kernel density estimation (KDE).
CSV JSON LATEX PICKLE SVG PDF PNG
{kind=link}
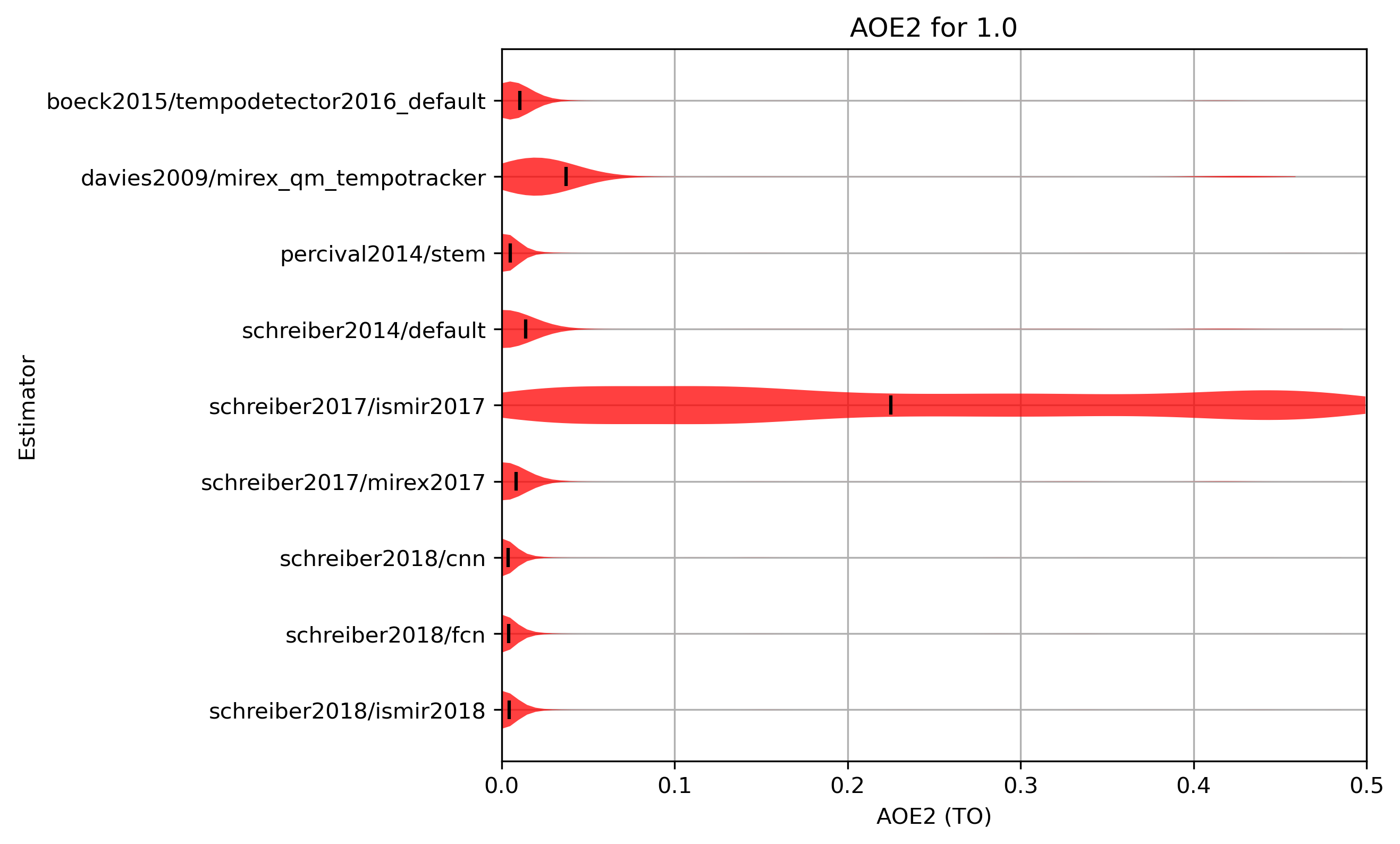{kind=link}
Significance of Differences
| Estimator | boeck2015/tempodetector2016_default | davies2009/mirex_qm_tempotracker | percival2014/stem | schreiber2014/default | schreiber2017/ismir2017 | schreiber2017/mirex2017 | schreiber2018/cnn | schreiber2018/fcn | schreiber2018/ismir2018 |
|---|---|---|---|---|---|---|---|---|---|
| boeck2015/tempodetector2016_default | 1.0000 | 0.0000 | 0.0020 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 |
| davies2009/mirex_qm_tempotracker | 0.0000 | 1.0000 | 0.0000 | 0.5283 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 |
| percival2014/stem | 0.0020 | 0.0000 | 1.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 |
| schreiber2014/default | 0.0000 | 0.5283 | 0.0000 | 1.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 |
| schreiber2017/ismir2017 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 1.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 |
| schreiber2017/mirex2017 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 1.0000 | 0.0000 | 0.0000 | 0.0224 |
| schreiber2018/cnn | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 1.0000 | 0.8289 | 0.0004 |
| schreiber2018/fcn | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.8289 | 1.0000 | 0.0009 |
| schreiber2018/ismir2018 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0224 | 0.0004 | 0.0009 | 1.0000 |
Table 10: Paired t-test p-values, using reference annotations 1.0 as groundtruth with AOE1. H0: the true mean difference between paired samples is zero. If p<=ɑ, reject H0, i.e. we have a significant difference between estimates from the two algorithms. In the table, p-values<0.05 are set in bold.
| Estimator | boeck2015/tempodetector2016_default | davies2009/mirex_qm_tempotracker | percival2014/stem | schreiber2014/default | schreiber2017/ismir2017 | schreiber2017/mirex2017 | schreiber2018/cnn | schreiber2018/fcn | schreiber2018/ismir2018 |
|---|---|---|---|---|---|---|---|---|---|
| boeck2015/tempodetector2016_default | 1.0000 | 0.0000 | 0.0000 | 0.0899 | 0.0000 | 0.0804 | 0.0000 | 0.0000 | 0.0000 |
| davies2009/mirex_qm_tempotracker | 0.0000 | 1.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 |
| percival2014/stem | 0.0000 | 0.0000 | 1.0000 | 0.0000 | 0.0000 | 0.0228 | 0.0948 | 0.1958 | 0.2987 |
| schreiber2014/default | 0.0899 | 0.0000 | 0.0000 | 1.0000 | 0.0000 | 0.0004 | 0.0000 | 0.0000 | 0.0000 |
| schreiber2017/ismir2017 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 1.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 |
| schreiber2017/mirex2017 | 0.0804 | 0.0000 | 0.0228 | 0.0004 | 0.0000 | 1.0000 | 0.0003 | 0.0007 | 0.0018 |
| schreiber2018/cnn | 0.0000 | 0.0000 | 0.0948 | 0.0000 | 0.0000 | 0.0003 | 1.0000 | 0.5200 | 0.2761 |
| schreiber2018/fcn | 0.0000 | 0.0000 | 0.1958 | 0.0000 | 0.0000 | 0.0007 | 0.5200 | 1.0000 | 0.2794 |
| schreiber2018/ismir2018 | 0.0000 | 0.0000 | 0.2987 | 0.0000 | 0.0000 | 0.0018 | 0.2761 | 0.2794 | 1.0000 |
Table 11: Paired t-test p-values, using reference annotations 1.0 as groundtruth with AOE2. H0: the true mean difference between paired samples is zero. If p<=ɑ, reject H0, i.e. we have a significant difference between estimates from the two algorithms. In the table, p-values<0.05 are set in bold.
AOE1 on Tempo-Subsets
How well does an estimator perform, when only taking a subset of the reference annotations into account? The graphs show mean AOE1 for reference subsets with tempi in [T-10,T+10] BPM. Note that the graphs do not show confidence intervals and that some values may be based on very few estimates.
AOE1 on Tempo-Subsets for 1.0
Figure 22: Mean AOE1 for estimates compared to version 1.0 for tempo intervals around T.
CSV JSON LATEX PICKLE SVG PDF PNG
{kind=link}
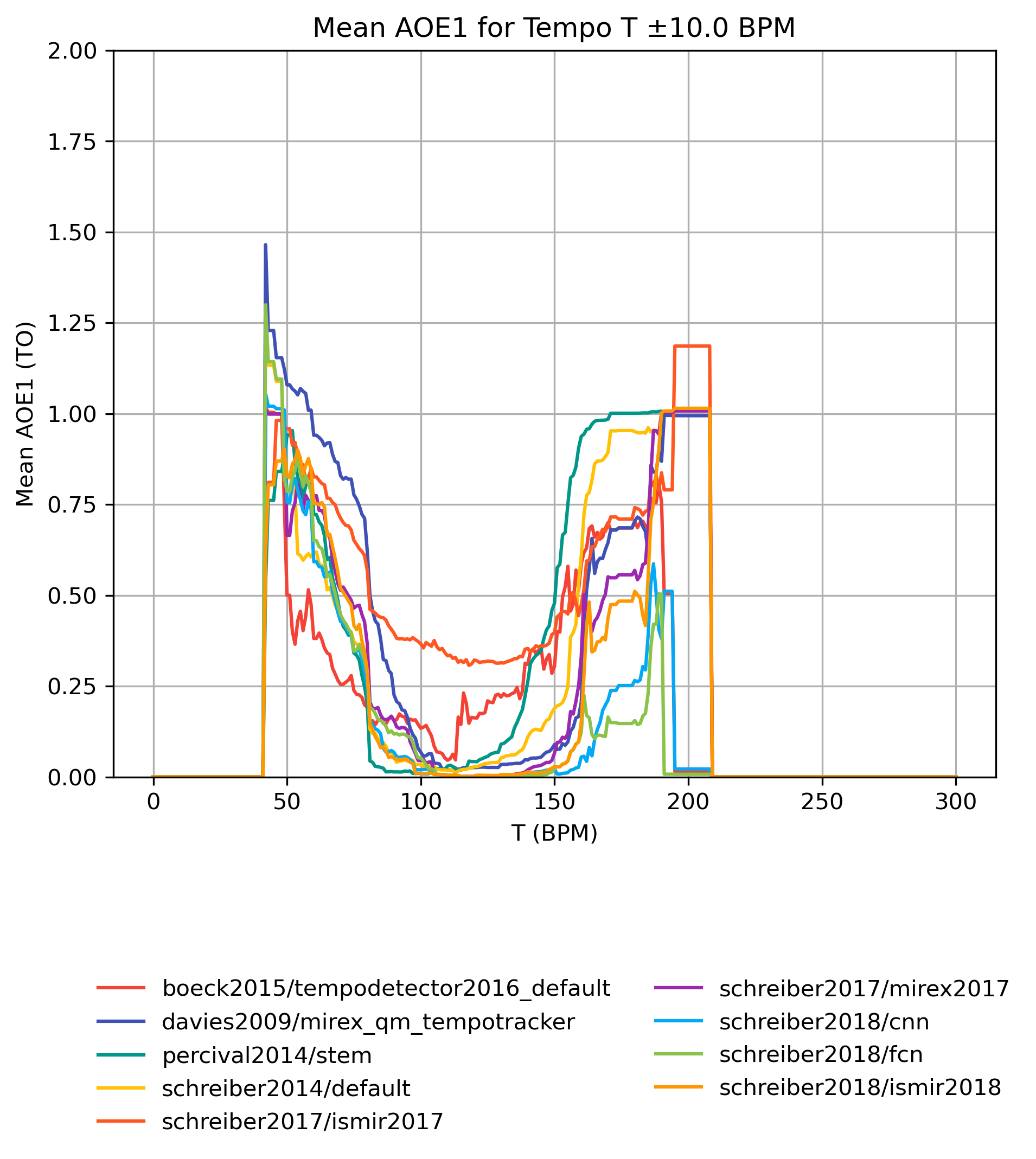{kind=link}
AOE2 on Tempo-Subsets
How well does an estimator perform, when only taking a subset of the reference annotations into account? The graphs show mean AOE2 for reference subsets with tempi in [T-10,T+10] BPM. Note that the graphs do not show confidence intervals and that some values may be based on very few estimates.
AOE2 on Tempo-Subsets for 1.0
Figure 23: Mean AOE2 for estimates compared to version 1.0 for tempo intervals around T.
CSV JSON LATEX PICKLE SVG PDF PNG
{kind=link}
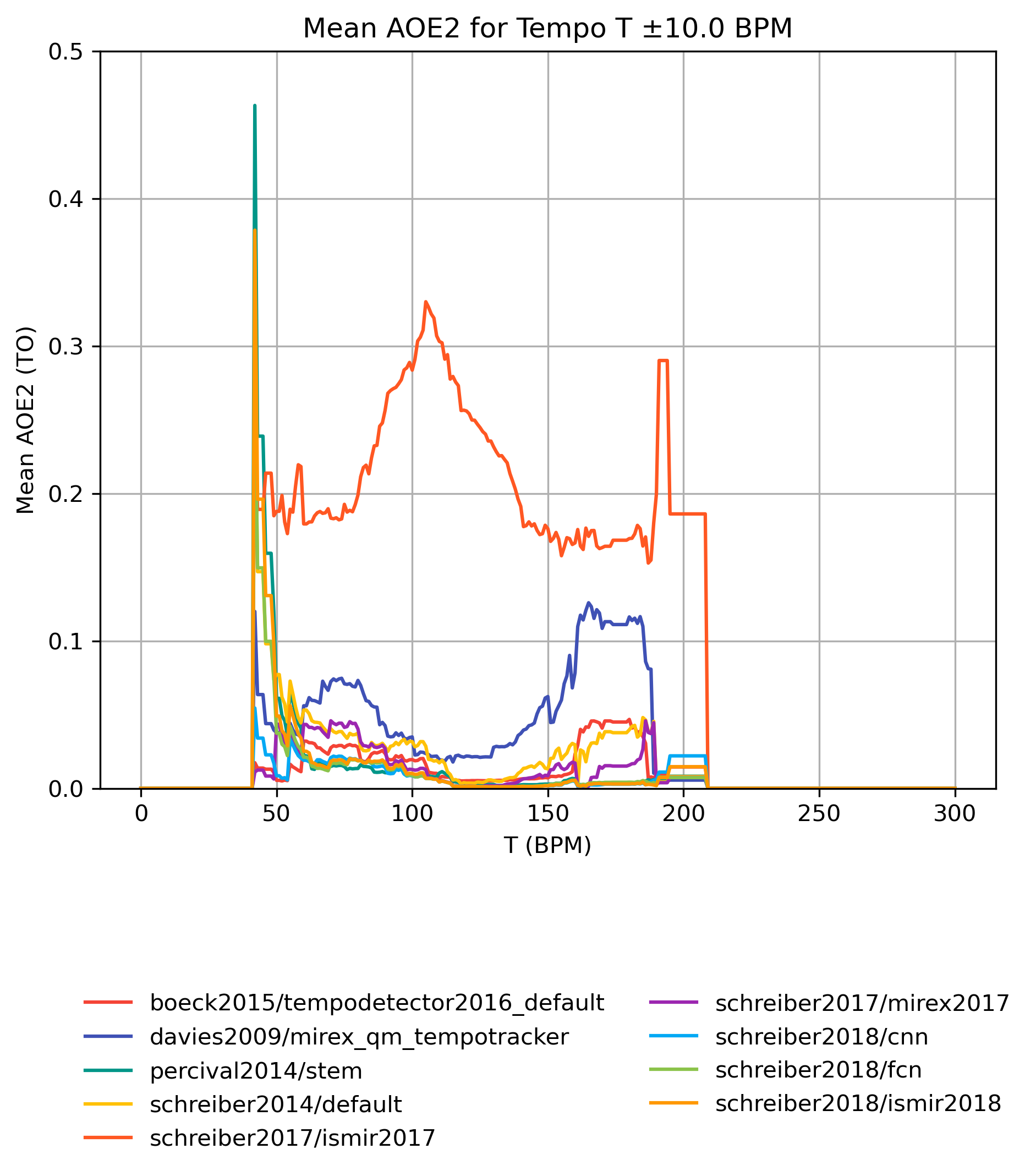{kind=link}
Estimated AOE1 for Tempo
When fitting a generalized additive model (GAM) to AOE1-values and a ground truth, what AOE1 can we expect with confidence?
Estimated AOE1 for Tempo for 1.0
Predictions of GAMs trained on AOE1 for estimates for reference 1.0.
Figure 24: AOE1 predictions of a generalized additive model (GAM) fit to AOE1 results for 1.0. The 95% confidence interval around the prediction is shaded in gray.
CSV JSON LATEX PICKLE SVG PDF PNG
{kind=link}
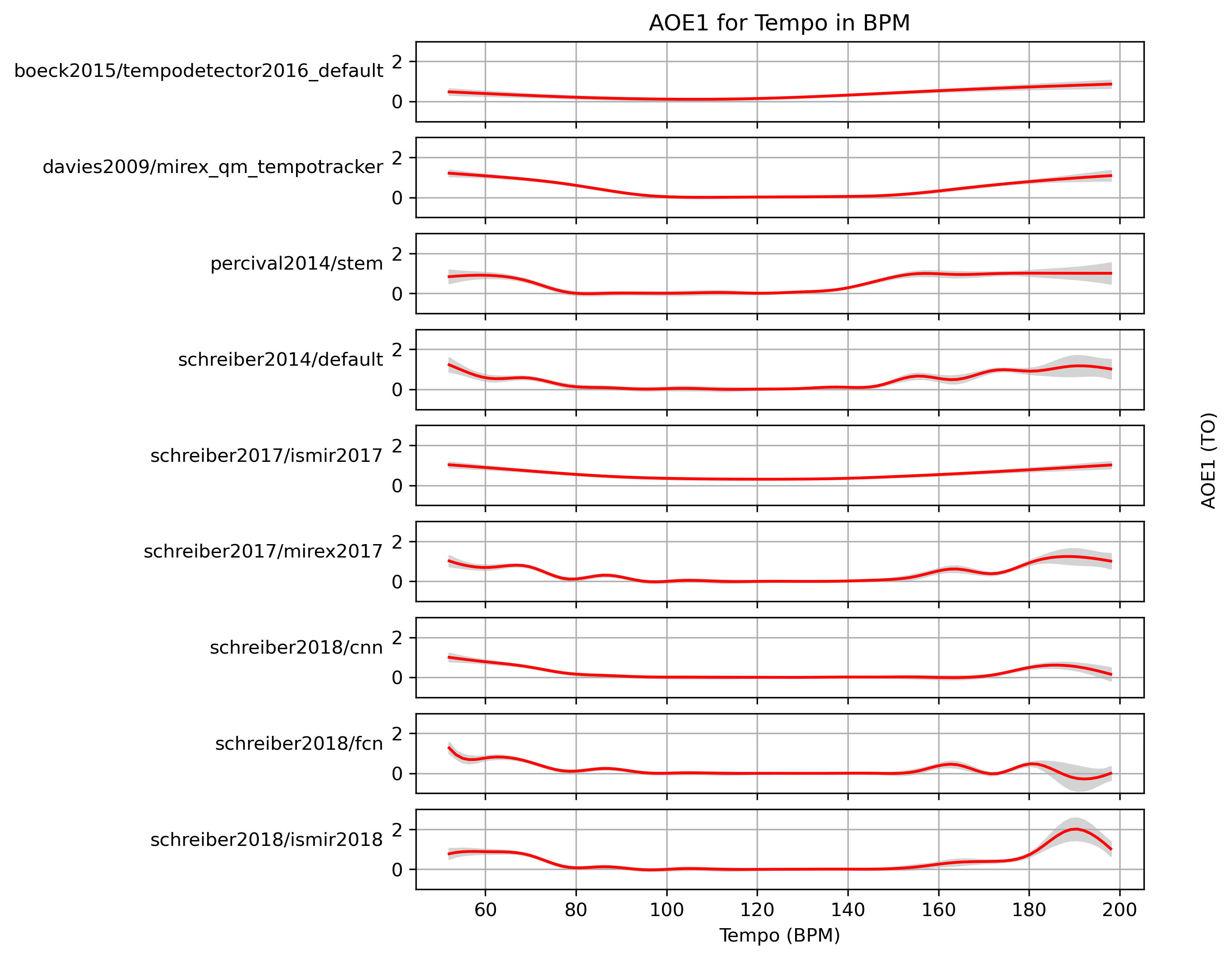{kind=link}
Estimated AOE2 for Tempo
When fitting a generalized additive model (GAM) to AOE2-values and a ground truth, what AOE2 can we expect with confidence?
Estimated AOE2 for Tempo for 1.0
Predictions of GAMs trained on AOE2 for estimates for reference 1.0.
Figure 25: AOE2 predictions of a generalized additive model (GAM) fit to AOE2 results for 1.0. The 95% confidence interval around the prediction is shaded in gray.
CSV JSON LATEX PICKLE SVG PDF PNG
{kind=link}
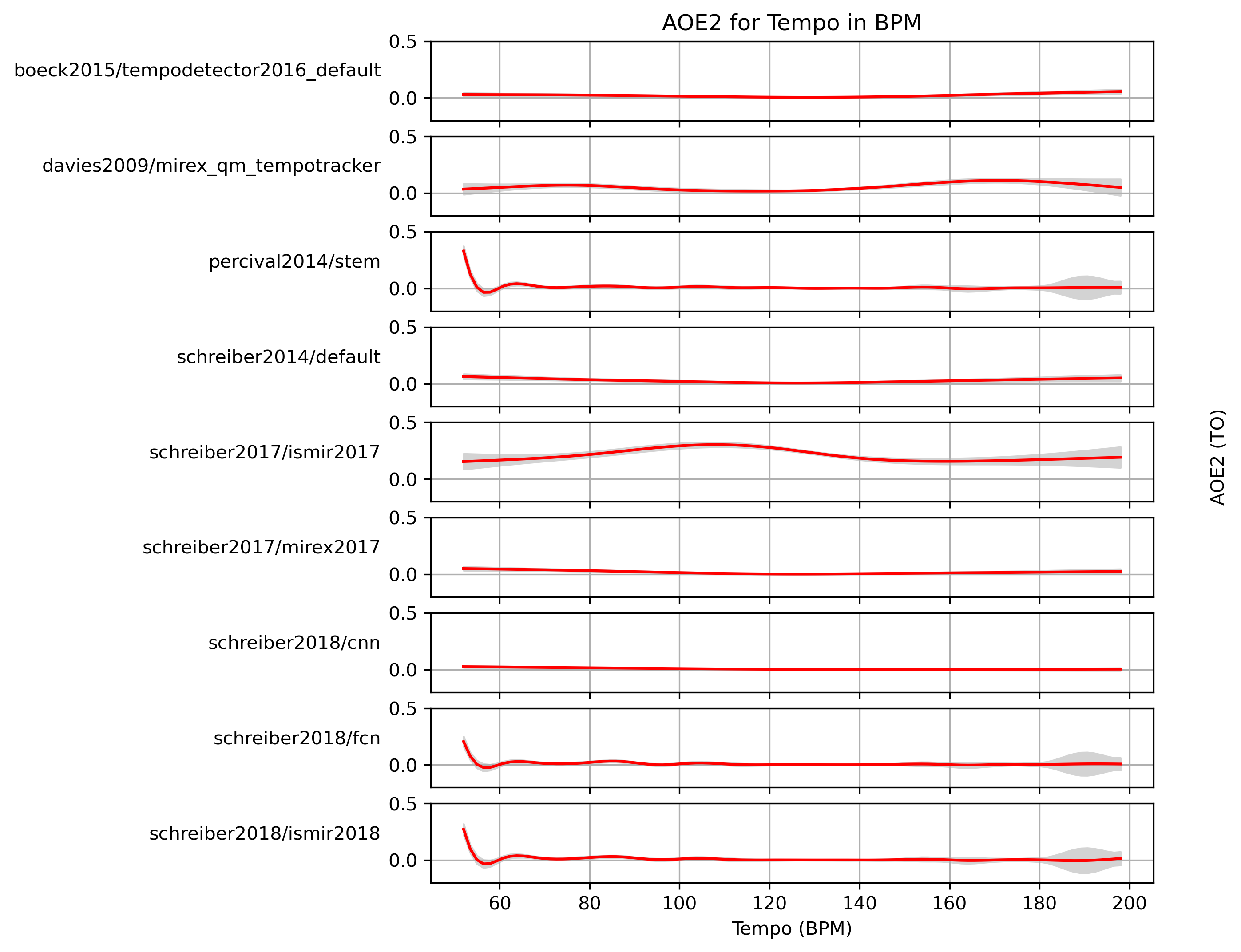{kind=link}
AOE1 for ‘tag_open’ Tags
How well does an estimator perform, when only taking tracks into account that are tagged with some kind of label? Note that some values may be based on very few estimates.
AOE1 for ‘tag_open’ Tags for 1.0
Figure 26: AOE1 of estimates compared to version 1.0 depending on tag from namespace ‘tag_open’.
{kind=link}
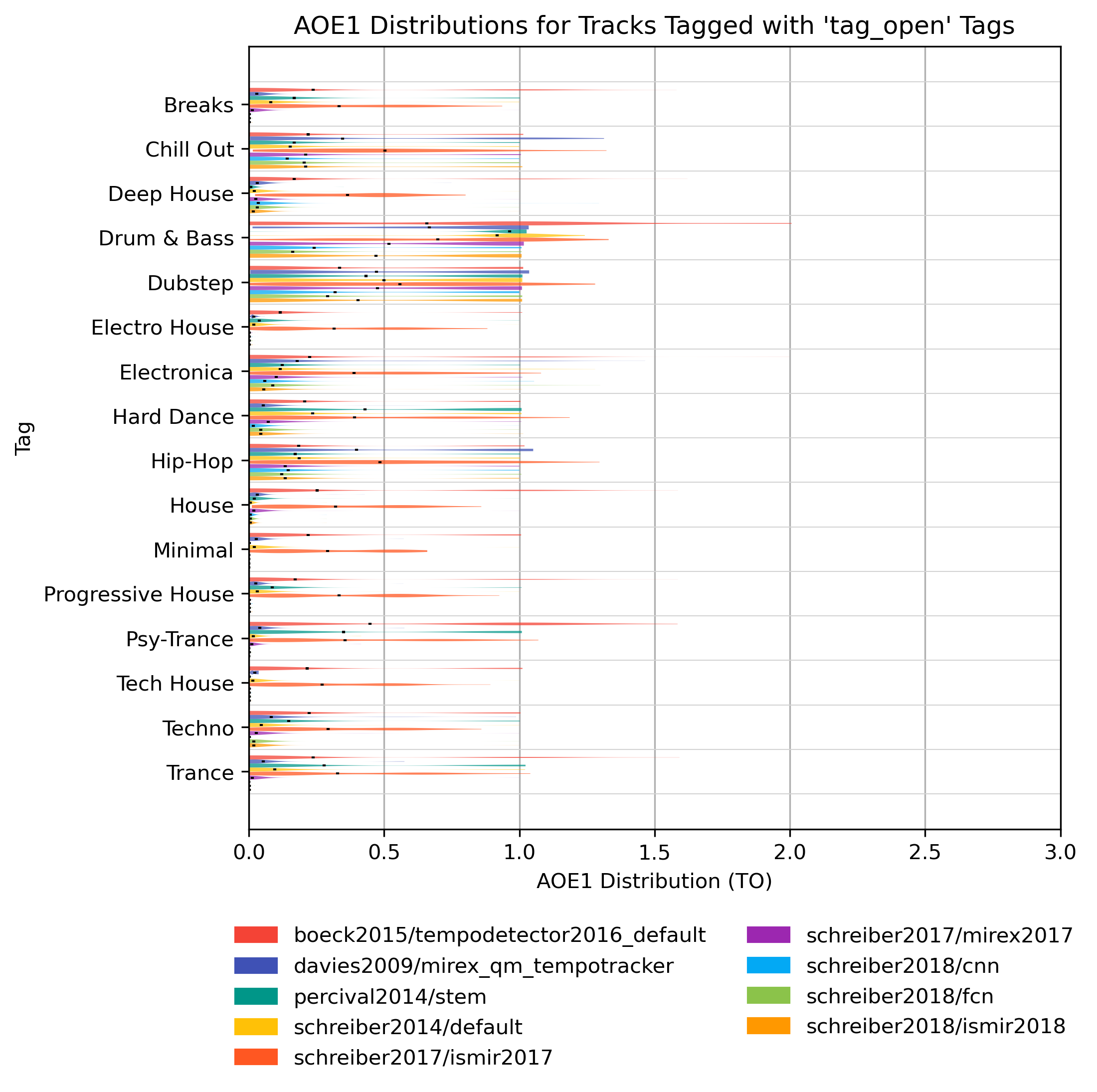{kind=link}
AOE2 for ‘tag_open’ Tags
How well does an estimator perform, when only taking tracks into account that are tagged with some kind of label? Note that some values may be based on very few estimates.
AOE2 for ‘tag_open’ Tags for 1.0
Figure 27: AOE2 of estimates compared to version 1.0 depending on tag from namespace ‘tag_open’.
{kind=link}
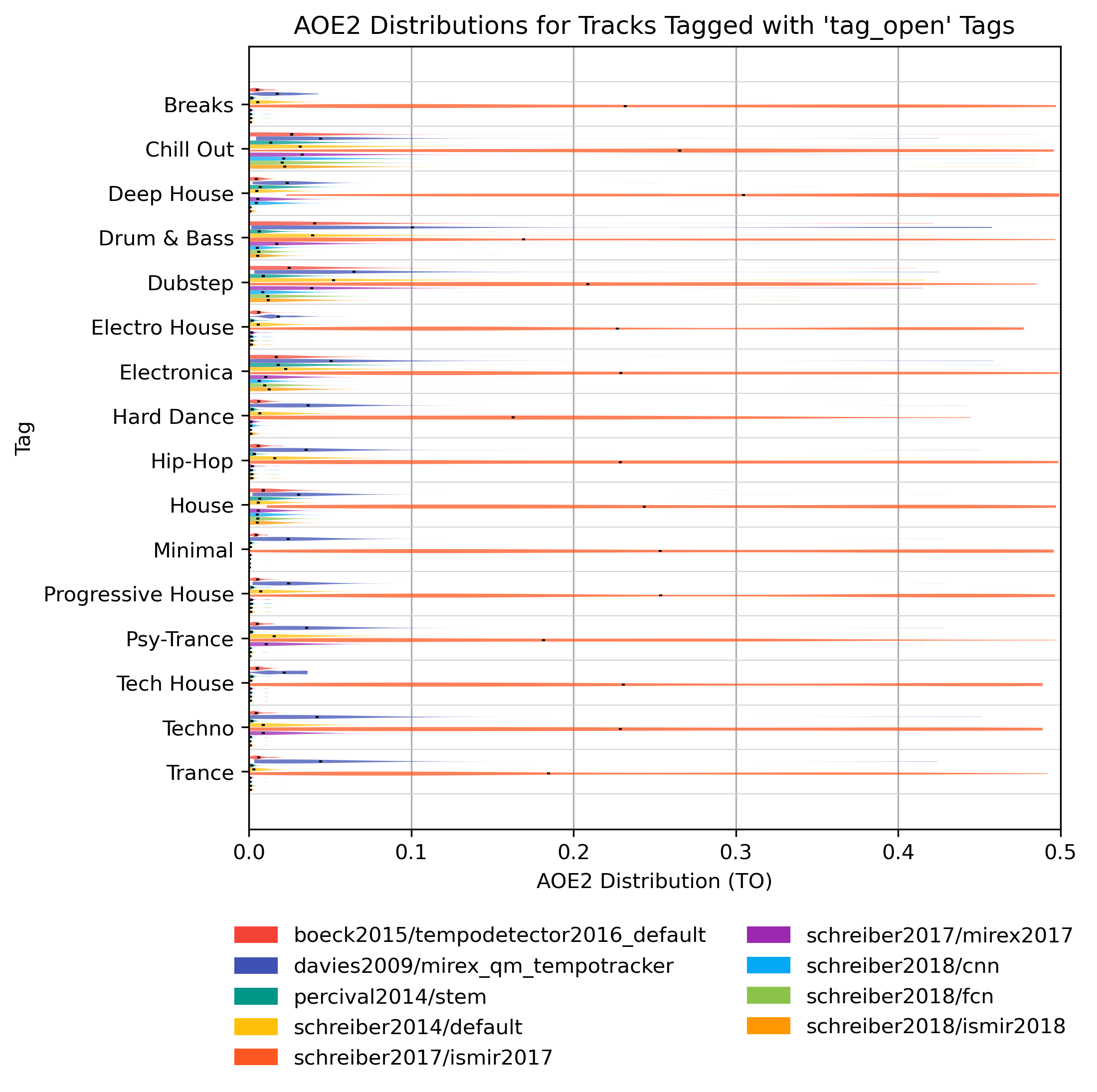{kind=link}
Generated by tempo_eval 0.1.1 on 2022-06-29 18:29. Size L.